
Page 40 - 《爆炸与冲击》2026年第5期
P. 40
第 46 卷 刘传志,等: 基于深度学习的亚稳态高熵合金高应变率冲击响应预测 第 5 期
散化为 30 个数据点。这样,微观组织、载荷条件以及相应的宏观力学响应(包括应力-应变曲线和相体
积分数的演变)作为输入与输出,用于训练卷积神经网络模型。
如前所述,通过晶体塑性模拟获得了不同微观结构在拉伸、压缩和剪切载荷条件下的宏观力学响
应。然后,这些响应通过特定的表示方法转换为用于卷积神经网络模型训练的数据集。训练前,数据集
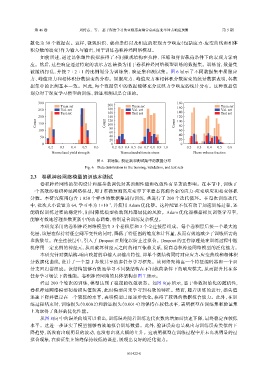
被随机打乱,并按 7∶2∶1 的比例划分为训练集、验证集和测试集。图 6 显示了不同数据集中屈服应
力、峰值应力和相体积分数演变的分布。屈服应力、峰值应力和相体积分数演变的统计数据表明,各数
据集中的比例基本一致。因此,每个数据集中的数据能够充分反映力学响应的统计分布。这种数据集
划分对于深度学习模型的训练、验证和测试是合理的。
300 180
Train set 200 Train set 160 Train set
250 Val. set 180 Val. set Val. set
Test set 160 Test set 140 Test set
200 140 120
Count 150 Count 120 Count 100
100
80
100 80 60
60
50 40 40
20 20
0 0 0
0.2 0.3 0.4 0.5 0.6 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 0.2 0.3 0.4 0.5 0.6
Normalized yield strength Normalized ultimate stress Phase volume fraction
图 6 训练集、验证集和测试集中的数据分布
Fig. 6 Data distribution in the training, validation, and test sets
2.3 卷积神经网络模型的训练和测试
卷积神经网络的架构设计和超参数调优对其预测性能和收敛性有显著的影响。在本节中,训练了
一个高效的卷积神经网络模型,用于准确预测高应变率下亚稳态高熵合金的应力-应变响应和相变体积
分数。本研究使用包含 1 050 个样本的数据集进行训练,共进行了 200 个迭代循环。在每次训练迭代
中,批次大小设置为 64,学习率为 1×10 ,并使用 Adam 优化器。这种配置不仅有助于加速训练过程,还
−3
能确保训练过程的稳定性,同时降低模型收敛到局部最优的风险。Adam 优化器根据梯度调整学习率,
能够有效地管理参数更新中的动态调整,特别适合训练复杂模型。
本研究采用的卷积神经网络模型由 3 个卷积层和 3 个全连接层组成。每个卷积层后接一个最大池
化层,该层在保持特征空间不变性的同时,降低了特征图的维度和计算量,从而有效地减少了训练所需的
参数数量。在全连接层中,引入了 Dropout 正则化以防止过拟合。Dropout 的工作原理是在训练过程中随
机停用一定比例的神经元,从而破坏神经元之间的相互依赖关系,提高卷积神经网络模型的泛化能力。
本研究针对微结构-响应映射的单输入双输出特性,即单个微结构同时对应应力-应变曲线和相体积
分数演化曲线,设计了一个基于参数共享的多任务学习框架。该网络架构由一个特征编码器和一个双
分支回归器组成。该结构能够有效地学习不同微结构在不同载荷条件下的响应模式,从而提升其在多
任务学习场景下的性能。卷积神经网络的具体架构如图 7 所示。
经过 200 个轮次的训练,模型达到了稳定的收敛状态。如图 8(a) 所示,鉴于参数初始化的随机性,
卷积神经网络模型初始损失值较高,此时模型尚未学习到有效的特征。然而,随着训练的进行,损失值
迅速下降并稳定在一个较低的水平,表明模型已经逐步优化,获得了较强的数据拟合能力。此外,在训
练过程结束时,训练损失(0.000 2)和验证损失(0.001 4)均保持在较低水平,表明模型在训练集和验证集
上均取得了良好的优化性能。
从图 8(b) 中的误差曲线可以看出,训练误差随着训练迭代次数的增加而快速下降,最终稳定在较低
水平。这进一步证实了模型能够有效地拟合训练数据。此外,验证误差也呈现出与训练误差类似的下
降趋势,既没有出现明显的波动,也没有出现大幅的上升。这表明模型在训练过程中并未出现明显的过
拟合现象,在验证集上始终保持较低的误差,展现出良好的泛化能力。
051422-8