
Page 37 - 《爆炸与冲击》2026年第5期
P. 37
第 46 卷 刘传志,等: 基于深度学习的亚稳态高熵合金高应变率冲击响应预测 第 5 期
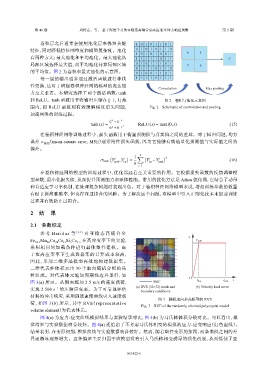
卷积层之后通常会使用池化层来保留关键 1 0 1 0 1 1 0 1
特征,同时降低特征图维度和模型复杂度。池化 0 1 0 1 0 1 1 0
1 0 1 0 1 0 0 1 6 5
有两种方式:最大池化和平均池化。最大池化从 1 1 1 1 1 0 1 1 7
局部区域选择最大值,而平均池化计算局部区域 0 1 0 1 1 1 0 1 7 6
0 1 1 1 0 1 1 0
的平均值。图 2 为卷积和最大池化的示意图。 0 1 0 0 1 1 0 1
每一层的输出通常通过激活函数进行非线 1 1 1 1 0 1 1 1
性变换,这对于增强卷积神经网络模型的表达能 Convolution Max pooling
力至关重要。本研究选择了两个激活函数:tanh
和 ReLU。tanh 函数用于将输出压缩在 [−1, 1] 范 图 2 卷积与池化示意图
围内,而 ReLU 函数则有效缓解梯度消失问题, Fig. 2 Schematic of convolution and pooling
加速网络的训练过程。
x
e −e −x
tanh(x) = , ReLU(x) = max(0, x) (15)
x
e +e −x
在卷积神经网络训练过程中,损失函数用于衡量预测值与真实值之间的差异。对于回归问题,均方
误差 σ MSE (mean-square error,MSE)通常用作损失函数,因为它能够有效地量化预测值与实际值之间的
偏差。
n
( ) 1 ∑ ( ) 2
i
σ MSE Y i ,Y i = Y −Y i (16)
pred tar tar pred
n
i=1
在卷积神经网络模型的训练过程中,优化器起着至关重要的作用。它根据损失函数的反馈调整模
型参数,最小化损失值,从而提升预测能力和整体性能。常用的优化方法是 Adam 优化器,它结合了动量
和自适应学习率机制,在处理复杂问题时表现出色。对于卷积神经网络模型来说,增加训练参数的数量
有助于提高准确率,但也存在过拟合的风险。为了解决这个问题,在模型中引入正则化技术来加速训练
过程并有效防止过拟合。
2 结 果
2.1 参数标定
参 考 H a r i d a s 等 [ 3 4 ] 对 亚 稳 态 高 熵 合 金
v
Fe 38.5 Mn Co Cr Si Cu 在高应变率下的实验, v peak
1.5
5
20
20
15
采 用 相 同 的 加 载 条 件 进 行 晶 体 塑 性 建 模 。 由
于 在 高 应 变 率 下 生 成 数 据 集 的 计 算 成 本 较 高 ,
因 此 , 采 用 二 维 多 晶 模 型 高 效 地 构 建 数 据 集 。
二维代表性体积元由 30 个取向随机分配的晶
粒组成。对代表体元施加周期性边界条件,如 O
图 3(a) 所示。从侧面施加 2.5 m/s 的速度载荷, PBC t rise t total t
(a) RVE (32×32) mesh and (b) Velocity load curve
实现 2 500 s 的压缩应变率。为了可靠地评估 boundary conditions
−1
材料的冲击响应,采用斜坡速度曲线引入速度载
图 3 随机取向多晶模型的 RVE
荷 , 如 图 3(b) 所 示 , 其 中 RVE( representative
Fig. 3 RVE of the randomly oriented polycrystal model
volume element)为代表体元。
图 4(a) 为应力-应变曲线模拟结果与实验结果对比,图 4(b) 为马氏体体积分数对比。可以看出,模
拟结果与实验数据吻合较好。图 4(a) 还给出了不考虑马氏体相变的模拟的应力-应变响应(红色虚线)。
结果表明,在变形初期,模拟曲线与实验数据吻合较好。然而,随着塑性变形的加剧,两条曲线之间的差
异逐渐显现并增大。这种偏差主要归因于该模型没有引入马氏体相变诱导的强化机制,从而低估了亚
051422-5