
Page 44 - 《爆炸与冲击》2026年第5期
P. 44
第 46 卷 刘传志,等: 基于深度学习的亚稳态高熵合金高应变率冲击响应预测 第 5 期
0.25
Train loss Train loss
0.25
Val. loss Val. loss
0.20
0.20
0.15
Loss 0.15 Loss 0.10
0.10
0.05
0.05 Train: 0.000 5
Val.: 0.002 1
0
0
0 50 100 150 200 0 50 100 150 200
Epoch Epoch
(c) R l =0.001 (d) R l =0.000 1
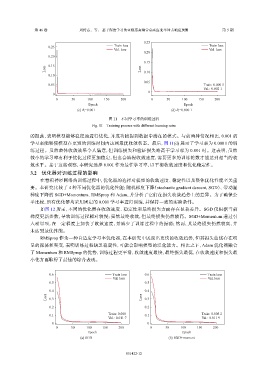
图 11 不同学习率的训练过程
Fig. 11 Training process with different learning rates
的振荡,表明模型能够稳定地进行优化,并成功捕捉到数据中潜在的模式。与前两种情况相比,0.001 的
学习率能够使模型在更短的训练时间内达到最优收敛状态。最后,图 11(d) 展示了学习率为 0.000 1 的训
练过程。虽然整体收敛效果令人满意,但训练损失和验证损失略高于学习率为 0.001 时。这表明,虽然
较小的学习率有利于优化过程更加稳定,但也会减慢收敛速度,需要更多的训练轮数才能达到相当的收
敛水平。基于这些观察,本研究选择 0.001 作为最佳学习率,以平衡收敛速度和优化稳定性。
3.2 优化器对训练过程的影响
在卷积神经网络的训练过程中,优化器的选择对模型的收敛速度、稳定性以及整体优化性能至关重
要。本研究比较了 4 种不同优化器的优化性能:随机梯度下降(stochastic gradient descent,SGD)、带动量
梯度下降的 SGD+Momentum、RMSprop 和 Adam,并分析了它们在损失收敛趋势上的差异。为了确保公
平比较,所有优化器均采用固定的 0.001 学习率进行训练,并保持一致的实验条件。
如图 12 所示,不同的优化器在收敛速度、稳定性和最终损失方面存在显著差异。SGD 仅根据当前
梯度更新参数,导致训练过程相对较慢;虽然最终收敛,但最终损失仍然较高。SGD+Momentum 通过引
入动量项,在一定程度上加快了收敛速度,并减少了训练过程中的振荡;然而,其最终损失仍然较高,并
未达到最优性能。
RMSprop 作为一种自适应学习率优化器,在本研究中展现出更快的收敛趋势,但其损失曲线存在明
显的振荡和突变,表明训练过程缺乏稳定性,可能会影响模型的泛化能力。相比之下,Adam 优化器融合
了 Momentum 和 RMSprop 的优势,训练过程更平滑,收敛速度最快,最终损失最低,在收敛速度和损失最
小化方面取得了最佳的综合表现。
0.6 Train loss 0.6 Train loss
Val. loss Val. loss
0.5 0.5
0.4 0.4
Loss 0.3 Loss 0.3
0.2 0.2
0.1 Train: 0.008 0.1 Train: 0.008 2
Val.: 0.011 7 Val.: 0.011 9
0 0
0 50 100 150 200 0 50 100 150 200
Epoch Epoch
(a) SGD (b) SGD+moment
051422-12