
Page 245 - 《软件学报》2025年第5期
P. 245
贺瑞芳 等: 基于去噪图自编码器的无监督社交媒体文本摘要 2145
经常共享较为相关的内容, 导致帖子之间经常具有较高的相似性. 这也是潜在关系在网络中占据较高比重的主要
原因.
为了回答第 2 个问题, 本文通过测试 DGAE 学习到的表示是否有助于减少网络中噪声关系的比率. 具体来说,
我们使用原始社交关系网络, 并利用与第 4.2 节相同的方式, 分别计算基于 DGAE 表示和基于 BERT 得到的原始
帖子内容表示的社交关系网络中的噪声比率. 为了衡量所学表示的有效性, 在计算噪声比率时, 都统一使用 BERT
θ , 以便在相同的噪声标准下进行比较. 另外, 由于 的取值会影响噪声关系的
θ
表示来计算帖子之间的相似度阈值
比例, 我们在实验中进一步探索了不同阈值下的噪声关系分布情况. θ 的取值按如下方式计算:
θ = minΦ+δ(maxΦ−minΦ) (19)
δ
θ
其中, δ 是一个在 [0, 1] 范围内的参数, 通过调整 δ 的取值, 可以改变阈值 的取值. 具体来说, 当 =0 时, θ 取最
δ
小值 minΦ ; 当 =1 时, θ 取最大值 maxΦ . 因此, 通过在 [0, 1] 范围内调整 δ 的取值, 可以使阈值 在 θ [ minΦ ,
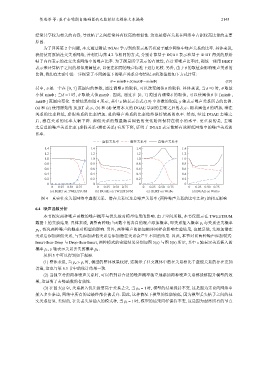
maxΦ ] 范围内变化. 实验结果如图 4 所示, 其中 x 轴表示公式 (19) 中参数的取值, y 轴表示噪声关系所占的比例.
(a) 和 (c) 使用原始的 BERT 表示, (b) 和 (d) 使用本文的 DGAE 学到的去噪之后的表示. 随着阈值 θ 的增加, 潜在
关系的比率降低, 虚假关系的比率增加. 总的噪声关系的比率始终保持较高的水平. 然而, 经过 DGAE 去噪之
后, 潜在关系的比率大幅下降. 虚假关系的数量随着阈值的变化始终保持在较小的水平. 更重要的是, 去噪
之后总的噪声关系比率 (虚假关系+潜在关系) 有所下降, 证明了 DGAE 表示能够有效降低网络中的噪声关系的
比率.
虚假关系率 潜在关系率 总噪声关系率
1.4 1.4 1.4 1.4
1.2 1.2 1.2 1.2
1.0 1.0 1.0 1.0
0.8 0.8 0.8 0.8
0.6 0.6 0.6 0.6
0.4 0.4 0.4 0.4
0.2 0.2 0.2 0.2
0 0 0 0
0 0.25 0.50 0.75 0 0.25 0.50 0.75 0 0.25 0.50 0.75 0 0.25 0.50 0.75
(a) BERT on TWEETSUM (b) DGAE on TWEETSUM (c) BERT on Weibo (d) DGAE on Weibo
图 4 真实社交关系网络中虚假关系、潜在关系以及总噪声关系率 (两种噪声关系的比率之和) 的相互影响
6.4 噪声函数分析
本节探究两种噪声函数的噪声概率与优先级对模型结果的影响. 由于空间所限, 本节仅展示在 TWEETSUM
数据上的实验结果. 具体来说, 调整两种噪声函数中的各自的噪声添加概率, 即关系插入概率 p i 与关系丢失概率
p d , 探究两种噪声的概率对模型的影响. 另外, 两种噪声的添加顺序同样会影响实验结果, 也就是说, 先添加潜在
关系后添加虚假关系, 与先添加虚假关系后添加潜在关系会产生不同的结果. 因此, 本节对比两种噪声添加模式:
Insert-then-Drop 与 Drop-then-Insert, 两种模式的实验结果分别如图 5(a) 与图 5(b) 所示, 其中 x 轴表示关系插入的
概率 p i , y 轴表示关系丢失的概率 p d .
从图 5 中可以得到如下观察.
p d > p i 时, 模型的整体效果较好, 这揭示了社交媒体中潜在关系相比于虚假关系的存在更加
(1) 整体来说, 当
普遍, 这也与第 6.3 节中的统计结果一致.
(2) 当独立考虑两种噪声关系时, 可以看到以合适的噪声概率独立地添加两种噪声关系都能够提升模型的效
果, 这证明了去噪函数的有效性.
(3) 在图 5(a) 中, 关系插入优先级要高于关系丢失, 当 p d = 1 时, 模型的结果保持不变. 这是因为无论向网络中
插入多少条边, 网络中所有的边最终都会被丢弃. 因此, 这种情况下模型的性能较低, 因为模型丢失帖子之间的社
交关系信息. 类似的, 在先丢失后插入的模式种, 当 p i = 1 时, 模型的结果同样保持不变, 这是因为最终所有的节点