
Page 243 - 《软件学报》2025年第5期
P. 243
贺瑞芳 等: 基于去噪图自编码器的无监督社交媒体文本摘要 2143
果均通过了显著性测试. 这是因为 ROUGE-L 主要用来评估输出摘要在语法上的流畅性, 然而抽取式摘要的语言
流畅性主要取决于抽取出的帖子的语言质量. 而抽取出的帖子主要是由社交媒体上的用户所撰写, 因此抽取式摘
要方法在 ROUGE-L 上的性能提升有限.
(2) 整体来说, 考虑社交关系的方法比仅考虑文本内容的方法具有更高的性能. 这说明社交网络中的社交关系
能够为内容分析提供额外的线索. 此外, Oracle 在 Weibo 数据上的得分相对较低, 这源于 Weibo 中的标准参考摘
要是生成式, 而模型的输出为抽取式摘要.
(3) 在所有整合了网络结构关系的方法中, DSNSum 模型在 R-1, R-L 与 R-SU*上均取得了最高的结果, 同时
在 R-L 上取得了具有竞争力的得分. 这源于在整合了社交关系的方法中, SNSR 采用基于规则的方法将社交关系
建模为简单的正则项, 因此该方法对噪声关系较为敏感, 且无法抵抗网络中噪声关系的干扰, 导致模型的灵活性与
泛化能力较低. SCMGR 模型利用图卷积网络整合帖子的社交关系信息与文本内容信息, 能够更加灵活地捕捉帖
子之间的社交关系结构, 但是该方法忽略了真实社交关系网络中的噪声关系, 因此在整合结构的过程中仍然会引
入额外的噪声偏差. DSNSum 模型则采用了一种新颖的“加噪-去噪”的学习模式, 通过向原始社交关系网络中添加
噪声构造训练数据, 然后设计了一种去噪图自编码器来降低社交关系网络中的噪声关系, 从而可以学习到更加准
确、对噪声关系更加鲁棒的帖子表示. 这种方式使得 DSNSum 模型能够更好地处理社交网络中的噪声关系, 从而
提高了模型的性能. 其次, DSNSum 模型在处理社交网络结构时, 采用了注意力机制, 这使得模型能够自动学习识
别不同节点之间关系的重要性, 从而更好地捕捉和利用社交网络结构.
(4) PacSum 取得了较低的得分, 原因在于 PacSum 是面向传统长文档的摘要方法. 该方法考虑文档中句子之间的
相对位置, 而在社交媒体环境下, 不同帖子之间通常没有严格的位置关系, 因此 PacSum 方法在社交媒体环境下取得了
较低的得分. SNSR 在 Weibo 数据上的性能较低, 这主要是该方法直接使用帖子的 TFIDF 表示进行重构, 所以模型倾
向于优化帖子之间的 1-gram 重合度来最小化重构损失. 这种方法在 TWEETSUM 上较为有效, 这是由于 TWEETSUM
中的参考摘要是从原始帖子集合中抽取的, 因此仅考虑 1-gram 重合度即可较大概率识别出原始帖子. 而 Weibo 中的
参考摘要为生成式, 因此无法直接根据 1-gram 重合度来识别原始帖子. DSNSum 能够学习帖子的分布式表示, 并且同
时包含了帖子的社交关系信息与文本内容信息, 因此能够同时取得较高的 ROUGE-1 与 ROUGE-2 得分.
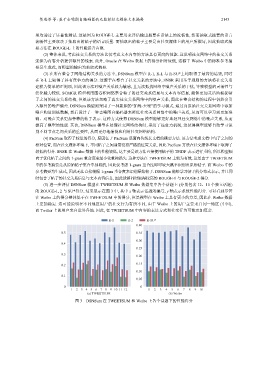
(5) 进一步评估 DSNSum 模型在 TWEETSUM 和 Weibo 数据集中各个话题上 (分别包含 12、10 个独立话题)
的 ROUGE-1, 2 与 SU*得分, 结果展示在图 3 中, 其中 x 轴表示话题的编号, y 轴表示系统性能得分. 可以看到尽管
在 Weibo 上的得分整体低于在 TWEETSUM 中的得分, 但是模型在 Weibo 上具有更小的方差, 因此在 Weibo 数据
上更加稳定. 这可能说明在不同地区用户的社交行为有所不同, 由于 Weibo 上的用户主要来自同一地区 (中国),
而 Twitter 上的用户来自世界各地. 因此, 在 TWEETSUM 中内容的表达方式和社交行为可能更加复杂.
R-1 R-2 R-SU*
0.40
0.5 0.35
0.30
0.4
0.25
0.3
0.20
0.15
0.2
0.10
0.1
0.05
0 0
1 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 6 7 8 9 10
(a) TWEETSUM (b) Weibo
图 3 DSNSum 在 TWEETSUM 和 Weibo 上各个话题下的性能得分