
Page 325 - 《软件学报》2025年第4期
P. 325
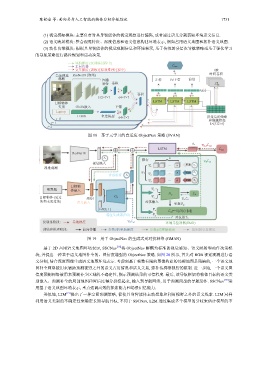
陈铂垒 等: 面向具身人工智能的物体目标导航综述 1731
(1) 视觉感知模块: 主要负责对具身智能体的视觉观察进行编码, 或者通过语义分割获取环境语义信息.
(2) 语义映射模块: 整合视觉特征、深度信息和语义信息构建环境表示, 例如占用语义地图和拓扑语义地图.
(3) 动作决策模块: 根据具身智能体的视觉观测信息和环境表示, 基于传统的分层次导航策略或基于强化学习
的导航策略进行路径规划和运动决策.
导航梯度 (仅训练过程中)
正向传播 nav
交互梯度 (训练过程和推理过程中) 1维
时间卷积
当前视觉 ResNet18 (冻结)
观测 图像 左转 向下看 前进
ϕ
特征 卷积 int
... π θ (s t )
卷积
512×7×7 64×7×7
目标物体 LSTM LSTM LSTM
类别 GloVe嵌入 平铺
Laptop
ObjectNav
1×300 全连接层 拼接后的策略
t=0 64×7×7 和隐藏状态
t=1 k×(512+6)
t=2
图 18 基于元学习的自适应 ObjectNav 策略 (SVAN)
a t
θ, ϕ nav
LSTM nav
Δ
ResNet18
s t k
缓存
视觉嵌入 ... 更新 ϕ ad
Δ
Ψ s s s t
视觉观测
Ψ ... x 更新 x t
合成特征 x t Ψ x
... a 更新 a t
Ψ a
目标物
喷雾瓶 体嵌入 Ψ s
D ω D
目标物体 (见过 SE(y) G θ Ψ x
的和未见过的) 语义嵌入 对抗输入 ω D
Δ
更新D w
z~N(0, 1)
Ψ x
ad =−E[D(x)·||a||]
特征生成器(FG) Ψ a
对抗损失
仅训练阶段: 导航梯度 θ ad 环境元鉴别器(EMD)
Δ
训练和推理阶段: 前向传播 参数θ的更新梯度 参数ϕ的更新梯度 鉴别器更新梯度
图 19 用于 ObjectNav 的生成式元对抗网络 (GMAN)
基于 2D 占用语义地图环境表示, SSCNav [18] 将 解耦为标准的视觉感知、语义映射和动作决策模
块, 并提出一种基于语义地图补全的、置信度增强的 ObjectNav 策略. 如图 20 所示, 首先对 RGB 视觉观测进行语
义分割, 结合深度图像生成语义地图环境表示. 考虑到基于帧数有限的图像构建的局部地图是残缺的, 一个语义地
图补全网络被用来辅助预测视野之外的语义占用情况和语义关系, 弥补传感器视野的限制. 进一步地, 一个语义置
信度预测网络被用来预测补全区域的不确定性, 指示预测结果的可信程度. 最后, 该导航框架将物体目标的语义类
别嵌入、预测补全的局部地图和置信度得分拼接起来, 输入到导航网络, 用于预测局部的导航动作. SSCNav [18] 采
用基于语义地图环境表示, 重点强调高效的探索能力和场景记忆能力.
类似地, L2M [19] 提出了一种空间预测策略, 促使具身智能体主动想象和利用视野之外的语义线索. L2M 同样
利用语义类别的不确定性来确定长期导航目标, 不同于 SSCNav, L2M 通过集成多个模型的分歧来估计模型的不