
Page 323 - 《软件学报》2025年第4期
P. 323
陈铂垒 等: 面向具身人工智能的物体目标导航综述 1729
征相结合构成了兼顾全局和局部场景先验的强大视觉表示. 为了防止具身智能体陷入局部死锁状态中, 模型构建
了一个记忆增强的试探策略网络 (tentative policy network, TPN), 在训练阶段通过模仿学习克隆专家轨迹, 学习逃
出死锁状态的动作. 在推理阶段, 即使具身智能体无法获得外部专家的监督, 试探策略网络首先检测具身智能体是
否陷入死锁状态, 然后通过历史经验中的死锁状态-动作数据对, 指导具身智能体做出逃离死锁状态的动作尝试.
最近, Du 等人 [37] 在 ORG+TPN 的基础上重点研究了导航过程中的历史信息对当前决策的影响, 提出了一种历史
启发的导航策略学习框架, 在 AI-THOR 数据集上取得了最佳的物体目标导航性能.
e t ′
CNN e t 路径点 +
起点
目标点
预测的
RGB图像 预测器 路径点 路径 多层感知机
路径点
e t 层归一化
CNN e t−1 M t Transformer编码器 Z t w t 辅助任务 +
深度图像 ... 状态表示 掩码后的多头
式, 并提出了一种在线学习机制, 根据实时的视觉观测更新场景图. 其中, 每个场景层的节点对应一个特定的场景
e t−L Critic 注意力机制
FC
v t Q K V 掩码
记忆 Actor
p t
任务观测
环境观测 状态编码器 强化学习 e t e t ... e t−L M t
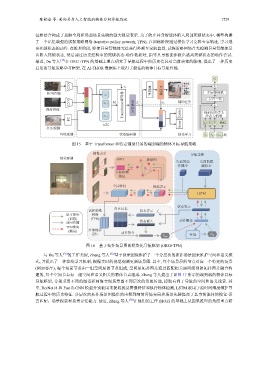
图 15 基于 Transformer 和特定辅助任务的端到端的物体目标导航策略
视觉表示 导航策略
视觉观测 ORG 场景图
先前的动 先前的隐
作概率 藏状态
目标检测
特征
全局特征 视觉表示
LSTM
状态表示
内在记忆
试探策略 状态表示 f
学习损失 网络 t
(训练) (TPN)
前向传播 状态嵌入 动作概率
TPN损失
(测试) 外部视觉 动作指令
记忆 环境 L til
L tpn
图 16 基于拓扑场景图的模块化导航框架 (ORG+TPN)
与 Du 等人 [36] 的工作类似, Zhang 等人 [32] 基于视觉图像维护了一个分层次的拓扑场景图来维护空间和语义模
(例如客厅), 每个场景节点由一组空间层的节点组成, 空间层拓扑图是通过匹配相关房间级别的拓扑图并融合构
建的, 每个空间节点有一组空间和语义相关的物体节点组成. Zhang 等人提出了如图 17 所示的端到端的物体目标
导航框架, 分别采用不同的图卷积网络实现场景图不同层次的消息传递, 提取有利于导航的空间和语义线索. 其
中, ResNet18 和 Fast R-CNN 模型分别被用来提取视觉图像特征和执行物体检测, LSTM 被用于沿时间维度维护导
航过程中的历史特征. 分层次的拓扑场景图提供的由粗到细的环境布局和场景先验提高了具身智能体的视觉-语
言匹配、场景探索和场景记忆能力. 最近, Zhang 等人 [38] 在他们的工作 (HOZ) 的基础上从因果推理的角度重点研