
Page 324 - 《软件学报》2025年第4期
P. 324
1730 软件学报 2025 年第 36 卷第 4 期
究了训练和测试环境之间的差异对物体目标导航性能的影响. 他们提出的基于布局的软总直接效应 (layout-based
soft total direct effect, L-sTDE) 框架大幅提升了 HOZ 的导航性能.
视觉特征 先前的
动作 隐藏状态
场景层
ResNet18
客厅 场景嵌入
S t+1
空间层
更新
S t 子目标空间
Faster R-CNN GCN LSTM 环境
当前空间 目标空间 nav
物体层 空间嵌入
抽屉
笔记本
GCN
策略所强调的能力来看, 端到端的
沙发 电视 动作向量
桌面
盒子
物体嵌入
a t
物体注意力 a t
电视
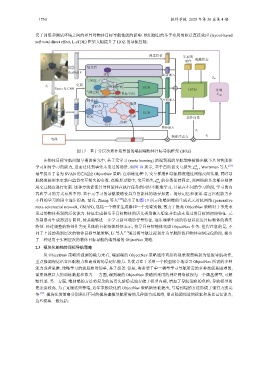
图 17 基于分层次拓扑场景图的端到端物体目标导航框架 (HOZ)
在物体目标导航问题早期的研究中, 基于元学习 (meta learning) 的端到端的导航策略被提出赋予具身智能体
学习如何学习的能力, 进而泛化到事先未见过的场景. 如图 18 所示, 基于自监督交互损失 L ϕ , Wortsman 等人 [39]
int
最早提出了名为 SVAN 的自适应 ObjectNav 策略. 在训练过程中, 交互梯度和导航梯度通过网络反向传播, 同时导
ϕ
航梯度被用来更新自监督交互损失的参数. 在推理过程中, 交互损失 L 的参数保持固定, 而网络的其余部分则使
int
用交互梯度进行更新. 这种方法促使具身智能体在执行任务的同时不断地学习, 只是在不同的学习阶段, 学习的内
容和学习的方式有所不同. 基于元学习的导航策略使具身智能体的场景探索、场景记忆和视觉-语言匹配能力在
不同的学习阶段中逐步提高. 最近, Zhang 等人 [40] 提出了如图 19 所示的端到端的生成式元对抗网络 (generative
meta-adversarial network, GMAN), 包括一个特征生成器和一个元鉴别器, 致力于提高 ObjectNav 策略对于事先未
见过的物体类别的泛化能力. 特征生成器基于目标物体的语义类别嵌入想象并生成未见过的目标的初始特征. 元
鉴别器对生成器进行监督, 使其能够进一步学习新环境的背景特征, 逐步调整生成的特征以接近目标物体的真实
特征. 经过调整的特征作为更具体的目标物体特征表示, 指导具身智能体完成 ObjectNav 任务. 值得注意的是, 不
同于上述的类别层次的物体目标导航策略, Li 等人 [33] 通过将导航过程划分为导航阶段和物体实例定位阶段, 提出
了一种适用于实例层次的物体目标导航的端到端的 ObjectNav 策略.
2.3 模块化的物体目标导航策略
从 ObjectNav ObjectNav 策略通常直接将视觉观察映射为低级导航动作,
重点强调视觉语言匹配能力和高效的场景记忆能力. 其优点在于采用一个模型综合地学习 ObjectNav 所需的多种
能力或者思维, 策略学习的流程相对简单, 易于部署. 但是, 寄希望于单一模型学习导航所需的多种技能是困难的,
需要规模巨大的训练数据和算力. 一方面, 端到端的 ObjectNav 策略所采用的神经网络被视为一个黑盒模型, 可解
释性差. 另一方面, 端到端的方法将复杂的场景先验隐式地存储于模型内部, 增加了导航策略的负担, 导致模型的
复杂度较高. 为了克服这些弊端, 近年来模块化的 ObjectNav 策略陆续被提出, 与端到端的方法形成了强有力的竞
争 [17] . 模块化的策略分别采用不同的模块建模导航所需的几种能力或思维, 重点强调高效的探索和场景记忆能力,
这些模块一般包括: