
Page 273 - 《软件学报》2025年第4期
P. 273
王永胜 等: 多模态信息抽取研究综述 1679
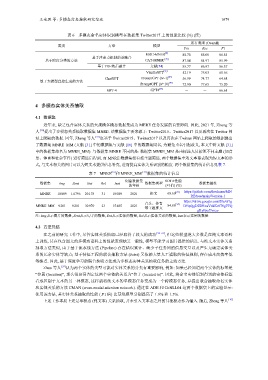
表 6 多模态命名实体识别模型在数据集 Twitter2017 上的性能比较 (%) (续)
所有类型 (Overall)
类别 方法 模型
Pre Rec F1
[8]
MRC-MNER 88.78 85.00 86.85
基于注意力机制的前融合
基于跨度分类的方法 CAT-MNER [39] 87.04 84.97 85.99
基于POE的后融合 文献[54] 85.77 86.97 86.37
VanillaGPT [43] 52.19 75.03 61.56
ChatGPT PromptGPT (N=1) [43] 56.99 74.77 64.68
基于大模型直接生成的方法 [43]
PromptGPT (N=10) 72.90 77.65 75.20
[57]
GPT-4 GPT4 - - 66.61
4 多模态实体关系抽取
系的冗余实体等缺点; 基于特征工程的联合抽取方法
4.1 数据集
近年来, 缺乏包含实体关系的大规模多模态数据集成为 MERE 任务发展的首要障碍. 因此, 2021 年, Zheng 等
人 [16] 提出了多模态关系抽取数据集 MNRE. 该数据集主要来源于: Twitter2015、Twitter2017 以及再次在 Twitter 网
站上爬取的数据. 同年, Zheng 等人 [31] 也基于 Twitter2015、Twitter2017 以及再次在 Twitter 网站上爬取的数据提出
了数据集 MNRE_MM (文献 [31] 中的数据集与文献 [16] 中的数据集同名, 为避免重名引起歧义, 本文中将文献 [31]
中的数据集命名为 MNRE_MM). 与数据集 MNRE 不同的是: 数据集 MNRE_MM 是由标注人员按照不同主题 (如音
乐、体育和社会事件) 进行筛选后得到, 而 MNRE 数据集没有按主题筛选. 两个数据集中的文本都表现为短文本的形
式, 与文本相关的图片可以为短文本提供信息补充, 进而提高实体关系识别的精度. 两个数据集的统计信息见表 7.
表 7 MNRE [16] 和 MNRE_MM [31] 数据集的统计信息
创建数据集 SOTA性能
数据集 Img Sent Ent Rel Inst 数据集类型 数据集链接
的年份 (F1值) (%)
MNRE 10 089 14 796 20 178 31 10 089 2021 推文 68.60 [47] https://github.com/thecharm/MN
RE/tree/main/Version-1
音乐、体育 [58] https://drive.google.com/file/d/1g
MNRE_MM 9 201 9 201 30 970 23 15 485 2021 84.86 D9ipQgDEDRxaVxkKr8T0gFFQ
等主题推文
gKyPpa7/view
注: Img表示图片的数量, Sent表示句子的数量, Ent表示实体的数量, Rel表示实体关系的数量, Inst表示实例的数量
4.2 方法总结
在之前的研究工作中, 尽管实体关系抽取已经取得了较大的成功 [59−61] , 但这些模型绝大多数是在纯文本语料
上训练, 其在包含图文的多模态语料上的性能表现缺乏一般性, 模型不能学习图片提供的信息. 与纯文本实体关系
抽取方法类似, 由于基于流水线方法 (Pipeline) 存在错误累计、缺少子任务间的信息交互以及产生无确定实体关
(Joint) 又依赖大量人工提取的特征规则, 存在成本高效率低
等缺点. 因此, 基于深度学习的联合抽取方法成为多模态实体关系抽取任务的主流方法.
Zhao 等人 [59] 认为两个实体的类型可能对实体关系的分类有重要影响, 例如: 如果已经知道两个实体的标签是
“位置 (location)”, 那么很容易判定这两个实体的关系为“位于 (located in)”. 因此, 将命名实体识别得到的实体标签
看成区别于文本的另一种模态, 这样就将纯文本的单模态任务变成为一个跨模态任务, 并提出联合抽取命名实体
和实体关系的方法 CMAN (cross-modal attention network). 通过在 ADE 和 CoNLL04 这两个数据集上的实验显示:
使用该方法, 其实体关系抽取的性能 ( F1 值) 比基线模型分别提高了 1.9% 和 1.5%.
上述工作本质上还是单模态 (纯文本) 关系抽取, 并未引入文本态之外的其他模态作为输入. 随后, Zheng 等人 [16]