
Page 274 - 《软件学报》2025年第4期
P. 274
1680 软件学报 2025 年第 36 卷第 4 期
引入包含图文的多模态关系抽取任务, 并分别通过 GloVe+CNN [62] 、BertNRE [63] 和 BERT+CNN [16] 的变体方法
(GloVe+CNN(Att.) [16] 、BertNRE(Att.) [16] 、BERT+CNN(Att.) [16] 等) 证明了融合图片信息可提高实体关系抽取的性
能. 此外, 进一步引入远程监督方法 PCNN [64] 的变体 (PCNN(Lab.) [16] 、PCNN(Obj.) [16] 、PCNN(Att.) [16] 等), 实验结果
显示: PCNN 的变体在 MNRE 数据集上的性能均差于 PCNN 方法. 上述对比实验说明: 虽然融合图片信息可提高
实体关系抽取的性能, 但并不是所有多模态方法在性能上均优于单模态方法. 为了进一步提高模型性能, Wang 等人 [47]
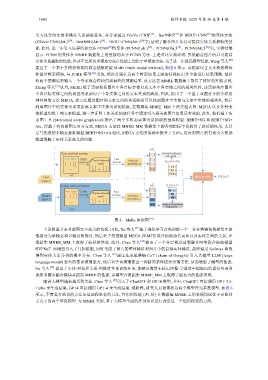
提出了一个基于多模态检索的联合抽取框架 MoRe (multi-modal retrieval), 如图 8 所示. 该框架包含文本检索模块
和图片检索模块, 与 PURE 模型 [61] 类似, 然后分别在这两个检索结果上添加特殊标记并单独进行结果预测, 最后
将两个预测结果输入一个专家混合模块得到最终的预测结果. 该方法在 MNRE 数据集上取得了较好的性能表现.
Zheng 等人 [31] 认为, MERE 除了需要捕获图片中各目标实体以及文本中各实体之间的相关性外, 还需要关注图片
中各目标实体之间的视觉关系到句子中各实体之间的文本关系的映射, 因此, 提出了一个基于双图对齐的多模态
神经网络方法 MEGA. 该方法通过图片和文本之间的关系映射可以找到图片中实体与文本中实体的相关性, 然后
利用图片中的实体关系来提高文本中实体关系的精度, 在数据集 MNRE_MM 上的实验表明: MEGA 以及各种变
体模型均优于纯文本模型, 进一步证明了在关系抽取任务中通过引入相关的图片信息是有效的. 此外, 他们基于情
景图工具 (pretrained scene graph tool) 提出了两个多模态实体关系抽取的基准模型: BERT+SG 和 BERT+SG+
Att., 得益于有效的图文对齐方法, MEGA 方法在 MNRE_MM 数据集上的各项指标中均取得了较好的结果, 尤其
是与先进的多模态基准模型 BERT+SG+Att.相比, MEGA 方法的准确率提升了 5.8%, 这表明图片的有效引入帮助
模型缓解了实体关系歧义的问题.
x,Z T
Text retrieval system Text-retrieval-based
task model
Key Value BM25 Top-k retrieved Post
I,
retrieval process Retrieved P Q z | y ( x, Z T )
result knowledge Z T
... ...
KC
Text MoE module P(y| x,I)
input x
I Z
x,I,
| y (
)
Image retrieval system 通过生成思维链
x,Z I
P Q
z
Key Value k-NN Top-k retrieved Post
Image retrieval result process Retrieved
input I knowledge Z I
... ...
Image-retrieval-based
task model
KC
图 8 MoRe 框架图 [47]
上述模型并未考虑图文不相关的情况. 因此, Xu 等人 [41] 基于强化学习首先训练一个二分分类器将数据集中的
数据分为单模态和多模态两部分, 然后基于先进模型 MEGA 和 MTB 联合抽取命名实体以及实体之间的关系, 在
数据集 MNRE_MM 上取得了较好的性能. 此外, Chen 等人 [40] 提出了一个分层视觉前缀融合网络联合抽取模型
HVPNeT. 该模型引入了门控机制, 同时考虑了图片的整体特征和图片中的目标实体特征, 最终通过 Softmax 函数
得到实体关系分类的概率分布. Chen 等人 [57] CoT (chain of thought) 引入大模型 LLM (large
language model) 强大的常识推理能力, 然后基于该推理提出一种新的条件提示蒸馏方法, 从而增强了模型的性能.
Hu 等人 [58] 提出了实体-对象和关系-图像对齐预训练任务, 能够从海量未标记图像-字幕对中提取自监督信号来预
训练多模态融合模块并提高 MERE 的性能. 该模型在数据集 MNRE_MM 上取得了强有力的性能表现.
随着大模型越来越受到关注, Chen 等人 [57] 引入了 ChatGPT 和 GPT4 模型, 其中, ChatGPT 直接调用 GPT-3.5-
Turbo 来生成结果, GPT4 直接调用 GPT-4 来生成结果. 现阶段, 研究人员通常将这两个模型作为基准模型. 如表 8
所示, 不管是有监督的方法还是远程监督的方法, 它们的性能 ( F1 值) 在数据集 MNRE 上的表现均远优于无监督
方式下的两个基准模型. 与 MNER 类似, 基于大模型生成的外部知识进行改进是一个值得探索的方向.