
Page 275 - 《软件学报》2025年第4期
P. 275
王永胜 等: 多模态信息抽取研究综述 1681
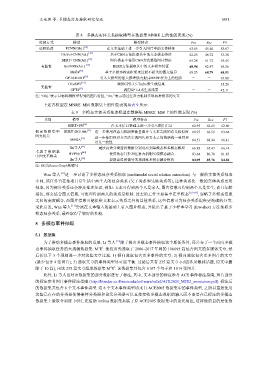
表 8 多模态实体关系抽取模型在数据集 MNRE 上的性能表现 (%)
监督方式 模型 模型特点 Pre Rec F1
远程监督 PCNN(Obj.) [16] 在文本基础上进一步引入图片中的实体特征 63.85 45.40 53.07
[16]
GloVe+CNN(Att.) 基于CNN方法提取其中的文本模态特征 62.25 46.72 53.38
[16]
BERT+CNN(Att.) 图片模态中使用CNN方法提取图片特征 65.28 61.72 63.45
有监督 BertNRE(Att.) [16] BERT方法提取其中的文本模态特征 68.94 62.47 65.56
[47]
MoRe 基于多模态检索框架来过滤不相关的图文信息 68.23 68.79 68.51
[57]
GPT4-BERT 引入大模型的强大推理能力提高MERE任务上的性能 - - 67.88
ChatGPT [57] 调用GPT-3.5-Turbo来生成结果 - - 35.20
无监督 [57]
GPT4 调用GPT-4来生成结果 - - 42.11
注: “Obj.”表示目标检测模型得到的图片特征, “Att.”表示通过注意力机制实现两种模态的交互
上述各模型在 MNRE_MM 数据集上的性能表现如表 9 所示.
表 9 多模态实体关系抽取模型在数据集 MNRE_MM 上的性能表现 (%)
态事件抽取任务的大规模数据集: M E . 他们首先选取了
类别 模型 模型特点 Pre Rec F1
BERT+SG [31] 在文本信息基础上进一步引入图片信息 62.95 62.65 62.80
假 定 数 据 集 中 BERT+SG+Att. [31] 进一步使用注意力机制来衡量图片与文本之间的语义相似度 60.97 66.56 63.64
图文相关 进一步使用图对齐方法实现图片和文本之间的结构一致性和
MEGA [31] 64.51 68.44 66.41
语义一致性
Xu等人 [41] 通过高效分类器将数据分别对应到单模态和多模态模型 66.83 65.47 66.14
考 虑 了 数 据 集 HVPNeT [40] 使用动态门控和注意力机制实现模态融合
中图文不相关 83.64 80.78 81.85
Hu等人 [58] 提取自监督信号来预训练多模态融合模块 84.95 85.76 84.86
注: SG为Scene Graph的缩写
Wan 等人 [11] 进一步讨论了多模态社会关系抽取 (multimodal social relation extraction). 与一般的实体关系抽取
不同, 该任务旨在抽取日常生活中两个人的社会关系 (父子关系和兄妹关系等), 这种关系比一般的实体关系更难
抽取, 因为部分关系还会涉及推理知识, 例如: 文本可得到两个人是家人, 图片信息可得到两个人是女生, 而且年龄
相仿, 那么结合图文信息, 可推理得到两人的关系是姐妹. 过去的工作主要集中在单模态 [65−69] , 忽略了多模态信息
之间的高度耦合, 而图片信息可能提供文本表示关系之外的其他关系, 这些信息可为社会关系提供更精确的分类.
受此启发, Wan 等人 [11] 尝试在文本输入的基础上引入图片模态, 并提出了基于少样本学习 (few-shot) 方法抽取多
模态社会关系, 最终取得了较好的性能.
5 多模态事件抽取
5.1 数据集
为了推动多模态事件抽取的发展, Li 等人 [13] 除了提出多模态事件抽取这个新任务外, 还公布了一个面向多模
2 2
2006–2017 年间的 108 693 篇包含图文的多媒体文章, 然
后按以下 3 个规则进一步对这些文章过滤: 1) 倾向选取包含更多事件的文章; 2) 倾向选取包含更多图片的文章
(最少包含 4 张图片); 3) 选取文章的事件类型尽可能平衡. 过滤后共有 235 篇文章 (可能涉及敏感话题, 原文中删
除了 10 篇), 由这 235 篇文章组成数据集 M E . 该数据集共包含 6 167 个句子和 1 014 张图片.
2 2
此外, Li 等人也对该数据集的部分数据进行了标注, 其中, 文本部分的标注参考 ACE 事件标注指南, 图片部分
的标注参考图片事件标注指南 (http://blender.cs.illinois.edu/software/m2e2/ACL2020_M2E2_annotation.pdf). 标注后
的数据集共包含 8 个文本事件类型. 这 8 个文本事件类型均来自 ACE2005 数据集中的事件类型, 之所以重复使用
这些已存在的分类是使得事件分类器和论元分类器可以直接接收多模态数据的输入而不需要在已标注的多模态
数据集上做联合训练. 同时, 还借助 imSitu 数据集拓展了原 ACE2005 数据集中的论元角色, 这样做的目的是使数