
Page 52 - 《软件学报》2025年第12期
P. 52
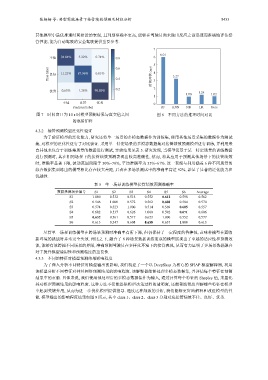
张杨杨 等: 典型驾驶场景下接管绩效预测及特征分析 5433
其他模型中最优推理时间相近的表现, 且判别准确率更高, 能够在驾驶员尚未做出反应之前迅速而准确地评估接
管性能, 能为自动驾驶的安全驾驶提供重要参考.
7
6.01
不佳 94.04% 5.22% 0.74% 0.8 6
True label 良好 11.23% 87.96% 0.81% 0.6 时间开销 (ms) 5 4 3 3.27
0.4
0.2 2
优秀 0.63% 1.28% 98.09% 1.24
1.00 1.02
1
不佳 良好 优秀 0
Predicted label RF KNN NB LR Ours
图 7 时间窗口为 10 s 时模型预测结果与真实值之间 图 8 不同方法的推理时间对比
的混淆矩阵
4.3.2 接管预测模型泛化性验证
为了验证模型的泛化能力, 研究还将单一场景的多模态数据作为训练集, 使用其他场景采集的数据作为测试
集, 对模型的泛化性进行了对比验证. 采用单一特定场景的多模态数据集对接管绩效预测模型进行训练, 并利用来
自其他未包含于训练集场景的数据进行测试, 实验结果见表 5. 研究发现, 当模型仅基于某一特定场景的训练数据
进行预测时, 其在相同场景下的接管绩效预测表现出较高准确性, 然而, 将其应用于预测其他场景下的接管绩效
时, 准确率显著下降, 波动范围局限于 50%–70%, 平均准确率为 55%–61%. 这一表现与利用涵盖 6 种不同场景的
综合数据集训练出的模型相比存在较大差距, 后者在多场景测试中的准确率高达 92%, 彰显了显著的泛化能力和
优越性.
表 5 单一场景训练模型接管绩效预测准确率
数据来源场景编号 S1 S2 S3 S4 S5 S6 Average
S1 1.000 0.532 0.518 0.552 0.612 0.598 0.562
S2 0.546 1.000 0.572 0.562 0.608 0.584 0.574
S3 0.574 0.523 1.000 0.514 0.569 0.605 0.557
S4 0.602 0.537 0.626 1.000 0.592 0.671 0.606
S5 0.632 0.561 0.517 0.623 1.000 0.552 0.577
S6 0.613 0.547 0.608 0.658 0.637 1.000 0.613
尽管单一场景训练模型在跨场景预测时准确率有所下降, 但仍保持了一定程度的鲁棒性, 意味着模型在面临
新环境的挑战时并未完全失效. 相比之下, 融合了 6 种场景数据训练而成的模型展现出了卓越的适应性和预测效
能, 能够有效跨越不同场景的界限, 准确预测驾驶员在多样化环境下的接管表现, 从而有力证明了多场景数据融合
对于提升模型通用性和预测精度的重要性.
4.3.3 不同的特征对模型预测结果影响程度
为了深入分析不同特征对模型输出的影响, 我们构建了一个以 DeepShap 为核心的 SHAP 模型解释器, 利用
该模型分析不同特征对神经网络预测结果的影响程度. 该解释器能够处理多模态数据集, 并评估每个特征在预测
结果中的贡献. 具体来说, 我们使用预处理后的多模态数据集作为输入, 通过计算每个特征的 Shapley 值, 来量化
其对模型预测结果的影响程度. 这种方法不仅能提供模型决策过程的透明度, 还能帮助我们理解哪些特征在模型
中起到关键作用, 从而为进一步优化模型提供指导. 通过这种细致的分析, 我们能够更好地解释和改进模型的性
能. 模型输出的影响程度结果如图 9 所示, 其中 class 1、class 2、class 3 分别对应接管绩效不佳、良好、优秀.