
Page 236 - 《软件学报》2025年第12期
P. 236
郑修林 等: 知识图谱补全技术及应用 5617
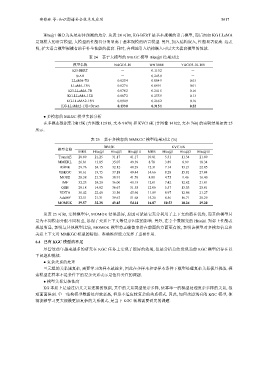
Hits@1 得分为头尾实体预测的均分. 从表 24 可知, KG-BERT 是基本规模的语言模型, 而后面如 KG LLaMA
是规模大的语言模型, 大模型的性能得分明显高于基本规模的语言模型. 另外, 加入结构嵌入, 性能显著提高. 这表
明, 扩大语言模型规模有助于补全性能的提高. 同时, 合理地引入结构嵌入可以大大提高模型的性能.
表 24 基于大模型的 MKGC 模型 Hits@1 结果对比
模型名称 NAGO3-10 WN18RR YAGO3-10-100
KG-BERT - 0.110 2 -
StAR - 0.243 0 -
LLaMA-7B 0.025 4 0.084 9 0.03
LLaMA-13B 0.027 6 0.099 1 0.01
KG-LLaMA-7B 0.078 2 0.241 5 0.16
KG-LLaMA-13B 0.087 2 0.255 9 0.13
KG-LLaMA2-13B 0.094 9 0.268 2 0.16
KG-LLaMA2-13B+Struct 0.133 0 0.315 1 0.22
● 多模态的 MKGC 模型实验分析
在多模态数据集 DB15K (含图像 12 818, 文本 9 078) 和 KVC16K (含图像 14 822, 文本 768) 的实验结果如表 25
所示.
表 25 基于多模态的 MMKGC 模型结果对比 (%)
DB15K KVC16K
模型名称
MRR Hits@1 Hits@3 Hits@10 MRR Hits@1 Hits@3 Hits@10
TransAE 28.09 21.25 31.17 41.17 10.81 5.31 11.34 21.89
MMKRL 26.81 13.85 35.07 49.39 8.78 3.89 8.99 18.34
RSME 29.76 24.15 32.12 40.29 12.31 7.14 13.21 22.05
VBKGC 30.61 19.75 37.18 49.44 14.66 8.28 15.81 27.04
MOSE 28.38 21.56 30.91 41.76 8.81 4.75 9.46 16.40
IMF 32.25 24.20 36.00 48.19 12.01 7.42 12.82 21.01
QEB 28.18 14.82 36.67 51.55 12.06 5.57 13.03 25.01
VISTA 30.42 22.49 33.56 45.94 11.89 6.97 12.66 21.27
AdaMF 32.51 21.31 39.67 51.68 15.26 8.56 16.71 28.29
MOMOK 39.57 32.38 43.45 54.14 16.87 10.53 18.26 29.20
从表 25 可知, 实验模型中, MOMOK 结果最好, 原因可能是它充分利用了上下文的潜在优势, 而其他模型只
是为不同模态分配不同权重, 忽视了关系上下文等复杂因素的影响. 另外, 在 2 个数据集的 Hits@1 指标上性能表
现最明显, 表明与其他模型比较, MOMOK 模型将正确答案排在前面的方面更有效, 表明该模型对多模态信息和
关系上下文对 MMKGC 模型的精细、准确推理能力发挥了重要作用.
6.4 已有 KGC 模型的不足
尽管这些年越来越多的研究在 KGC 任务上实现了很好的效果, 但是分析总结发现当前 KGC 模型仍存在以
下问题和挑战.
● 复杂关系的处理
三元组的关系越复杂, 需要学习的样本就越多, 因此在少样本和零样本条件下模型处理复杂关系极具挑战. 探
索模型在样本不足条件下的复杂关系表示是值得关注的课题.
● 模型关系复杂性高
KG 本质上是通过语义关系连接的数据, 其中的关系类型复杂多样, 依靠单一的模型处理复杂多样的关系, 很
难面面俱到. 单一结构模型数据处理效率高, 但是不适应较复杂的关系模式. 因此, 如何改进现有的 KGC 模型, 使
得能够学习更大规模更加复杂的关系模式, 是当下 KGC 领域需要研究的课题.