
Page 234 - 《软件学报》2025年第12期
P. 234
郑修林 等: 知识图谱补全技术及应用 5615
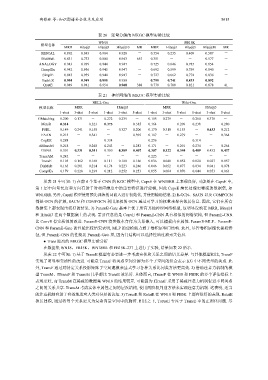
表 20 张量分解的 MKGC 模型实验比较
WN18 FB15K
模型名称
MRR Hits@1 Hits@3 Hits@10 MR MRR Hits@1 Hits@3 Hits@10 MR
RESCAL 0.892 0.843 0.904 0.928 - 0.354 0.235 0.409 0.587 -
DistMult 0.831 0.733 0.804 0.943 655 0.351 - - 0.577 -
ANALOGY 0.943 0.939 0.944 0.947 - 0.725 0.646 0.785 0.854 -
ComplEx 0.942 0.936 0.945 0.947 - 0.692 0.599 0.759 0.840 -
SimplE 0.943 0.939 0.944 0.947 - 0.727 0.662 0.774 0.838 -
TuckER 0.954 0.949 0.955 0.958 - 0.795 0.741 0.833 0.892 -
QuatE 0.949 0.941 0.954 0.960 388 0.770 0.700 0.821 0.878 41
表 21 神经网络的 MKGC 模型实验比较
NELL-One Wiki-One
模型名称 MRR Hits@5 MRR Hits@5
1-shot 3-shot 5-shot 1-shot 3-shot 5-shot 1-shot 3-shot 5-shot 1-shot 3-shot 5-shot
GMatching 0.200 0.171 - 0.272 0.235 - 0.185 0.279 - 0.260 0.370 -
MetaR 0.314 - 0.323 0.375 - 0.385 0.164 - 0.209 0.238 - 0.280
FSRL 0.149 0.241 0.158 - 0.327 0.206 0.170 0.318 0.153 - 0.433 0.212
FAAN 0.215 - 0.341 - 0.395 0.187 - 0.279 - - 0.364
CogKR 0.288 - - 0.334 - - 0.256 - - 0.314 - -
AMmodel 0.218 - 0.248 0.243 - 0.283 0.171 - 0.201 0.234 - 0.264
GANA 0.301 0.331 0.351 0.350 0.389 0.407 0.307 0.322 0.344 0.409 0.432 0.437
TransAM 0.242 - - - - - 0.225 - - - - -
TransE 0.105 0.162 0.168 0.111 0.180 0.186 0.036 0.040 0.052 0.024 0.027 0.057
DisMult 0.165 0.201 0.214 0.174 0.223 0.246 0.046 0.052 0.077 0.034 0.041 0.078
ComplEx 0.179 0.228 0.239 0.212 0.252 0.253 0.055 0.064 0.070 0.044 0.053 0.063
从表 21 中可知: 1) 在前 4 个基于 CNN 的 KGC 模型中, CapsE 在 WN18RR 上表现良好, 可能是在 CapsE 中,
第 1 层中向量长度和方向有助于对相应维度中的重要特征进行建模, 因此 CapsE 擅长处理更稀疏的数据集, 如
WN18RR. 另外, CapsE 模型使用预先训练的词嵌入进行初始化, 并使用辅助信息. 2) R-GCN、SACN 以及 COMPGCN
都是 GCN 的扩展, SACN 和 COMPGCN 利用加权的 GCN 通过可学习的权重来聚合邻居信息. 因此, 它们在所有
数据集上都表现出较好的结果. 3) ParamE-Gate 基本上优于所有其他神经网络模型, 这明显反映在 MRR, Hits@1
和 Hits@3 在两个数据集上的表现. 需要注意的是 ConvE 和 ParamE-CNN 具有相似的网络架构, 但 ParamE-CNN
比 ConvE 有实质性的改进. ParamE-CNN 将参数本身作为关系嵌入, 可以捕捉内在属性. ParamE-MLP、ParamE-
CNN 和 ParamE-Gate 的性能比较结果表明, MLP 的建模能力弱于卷积层和门结构. 此外, 尽管卷积层擅长提取特
征, 但 ParamE-CNN 的性能比 ParamE-Gate 差, 因为门结构可以选择性地过滤无关信息.
● Trans 距离的 MKGC 模型实验分析
在数据集 WN18、FB15K、WN18RR 和 FB15K-237 上进行了实验, 结果如表 22 所示.
从表 22 中可知: 1) 基于 TransE 模型有必要进一步考虑实体和关系之间的语义差异. 与其他模型相比, TransF
实现了明显和实质性的改进. 可能是 TransF 将关系空间分解为多个子空间的组合表示 KG 中不同类型的关系. 此
外, TransF 通过对特定关系投影矩阵子空间建模来显式学习各种关系比同类方法更高效. 2) 借助注意力机制的模
型 TransM、ITransF 和 TransAt 几乎都比 TransE 效果好. 具体而言, ITransF 在 WN18 和 FB5K 的多个评估指标上
表现更好, 而 TransM 在稀疏的数据集 WN18 的结果较差. 可能因为 ITransF 采用了稀疏注意力机制促进不同关系
之间的关系共享. TransAt 考虑实体中属性之间的层次结构, 使用两阶段判别方法来实现注意力机制. 这表明, 适当
的注意机制有助于有效地适应人类对分层的认知. 3) TorusE 和 RotatE 在 WN18 和 FB5K 上都有很好的表现. RotatE
擅长建模, 通过将每个关系定义为复杂向量空间中的旋转. 相比之下, TorusE 专注于 TransE 中的正则化问题. 尽