
Page 208 - 《软件学报》2025年第5期
P. 208
2108 软件学报 2025 年第 36 卷第 5 期
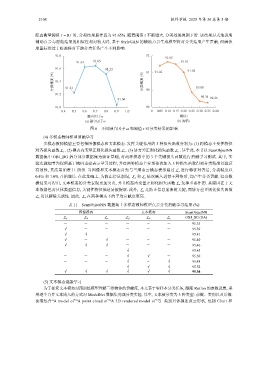
τ = 0.1 时, 分类结果最佳且为 τ 不断增大, 分类效果急剧下滑. 该结果显式地说明
距离衡量阈值 91.65%. 随着阈值
辅助点云与原始结果的相似性相对较大时, 基于 StyleGAN 的辅助点云生成模型将对分类结果产生贡献. 但阈值
度量标准过于松弛将对下游分类任务产生不利影响.
91.8 92
91.65
91.63 91.65 91.51
91.6 91.52 91 91.42 91.04
分类精度 (%) 91.4 91.23 分类精度 (%) 89.88
91.2 90
89.34 89.26
91.04
91.0 89
0.4 0.5 0.6 0.7 0.8 0.9 1.0 0 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40
融合因子ω 阈值τ
(a) 融合因子ω (b) 阈值τ
图 6 不同融合因子 ω 和阈值 τ 对分类结果的影响
(4) 多模态教师模型消融学习
多模态教师模型主要包括图像模态和文本模态. 发挥关键作用的 3 种损失函数分别为: (1) 跨模态不变性特征
对齐损失函数 L s . (2) 模态内变量正则化损失函数 L v . (3) 协方差正则化损失函数 L c . 基于此, 本节以 ScanObjectNN
数据集中 OBJ_BG 拆分部分数据集为验证基础, 对两种模态中的 3 个关键损失函数进行消融学习测试. 其中, 实
验实施细节为保留基于掩码重建表示学习过程, 并在两种模态上分别依次加入 3 种损失函数得到分类精度以验证
有效性, 其结果如表 11 所示. 当图像和文本模态首先与三维点云模态表示通过 L s 进行特征对齐后, 分类精度以
0.4% 和 1.0% 开始增长. 在此基础上, 为防止信息崩塌, L v 和 L c 依次嵌入进骨干网络后, 均产生分类贡献. 综合数
据结果可得出, 文本模态的分类表现更加突出, 并且模态内变量正则化损失函数 L v 发挥重要作用. 其原因在于文
L v 是防止信息崩溃的关键, 而协方差正则化损失函数
本数据包含具体类型信息, 关键性特征描述易被提取. 此外,
L c 用以解除关联性. 因此, L v 在两种模态下的平均贡献度更高.
表 11 ScanObjectNN 数据集上多模态教师模型点云分类消融学习结果 (%)
图像模态 文本模态 ScanObjectNN
L s L v L c L s L v L c OBJ_BG (OA)
- - - - - - 95.35
√ - - - - - 95.39
√ √ - - - - 95.41
√ - √ - - - 95.40
√ √ √ - - - 95.46
- - - √ - - 95.45
- - - √ √ - 95.50
- - - √ - √ 95.48
- - - √ √ √ 95.52
√ √ √ √ √ √ 95.54
(5) 文本模态消融学习
为了探究文本模态对预训练模型理解三维物体的贡献度, 本文基于零样本分类任务, 跟随 ReCon 的参数设置, 采
用逐个合并文本嵌入的方式对 ModelNet 数据集完成分类实验. 其中, 文本被分类为 3 种类型: 前缀、类别以及后缀.
前缀包含“A model of”“A point cloud of”“A 3D rendered model of”等. 类别具体描述点云形状, 包括 Chair 和