
Page 68 - 《软件学报》2025年第12期
P. 68
李春奕 等: 基于时序逻辑的需求文本隐含语义解析与推理 5449
实验结果表明, 当单词向量维度 300 时, 训练数据上的图像振荡幅度小、模型稳定性高, 并在训练轮次为
300 时, 验证集上分类准确率表现较好. 在接下来实验中本文将选取单词向量维度为 300 去构建文本向量去验证
本文所提方法的有效性.
• 问题 1: 数据预处理是否可以应对需求文本存在语义模糊性的问题, 准确识别其隐含的时序语义?
在数据预处理阶段, 对需求文本进行数据清洗以降低噪声, 并使用词性标注来汇集带有时序标签的特征信息,
同时删除信息熵较低的单词. 此外, 通过依存关系分析推断出句子中单词之间的语义关系, 从而提取单词之间的关
联性特征信息. 以上提取的特征信息用于突出文本时序逻辑语义特征信息, 并应对自然语言需求文本中语义描述
模糊性问题.
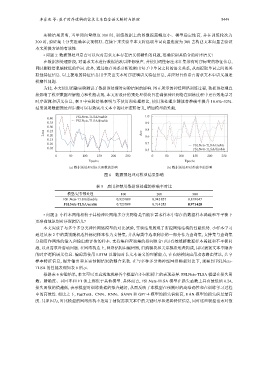
为此, 本文使用消融实验测试了数据预处理对实验结果的影响. 图 6 所示的神经网络训练过程, 数据预处理直
接影响了模型数据理解能力和性能表现. 本文所设计的预处理模块旨在确保神经网络在训练过程中更有效地学习
时序逻辑和语义信息, 表 5 中实验结果表明与不使用预处理相比, 使用预处理步骤能将准确率提升 18.6%–32%.
结果说明数据预处理步骤可以有效突出文本中的时序逻辑语义, 增加模型的性能.
FSLNets-TLSA/enable 1.0
0.40
FSLNets-TLSA/disable
0.35 0.9
0.30
0.8
Loss Acc
0.25
0.20
0.6
0.15
0.10 0.7
FSLNets-TLSA/enable
0.05
0.5 FSLNets-TLSA/disable
0 50 100 150 200 250 0 50 100 150 200 250
Epochs Epochs
(a) 数据预处理对损失函数的影响 (b) 数据预处理对准确率的影响
图 6 数据预处理对模型结果影响
表 5 启用和禁用数据预处理的准确率对比
模型/是否预处理 100 200 300
FSLNets-TLSA/disable 0.923 809 0.942 857 0.819 047
FSLNets-TLSA/enable 0.723 809 0.714 285 0.971 428
• 问题 2: 小样本网络相较于其他神经网络多分类网络是否能在需求样本中存在的数据样本稀疏和不平衡下
更准确地识别时序逻辑语义?
本文完成了与多个多分类神经网络模型的对比试验, 实验结果展现了所提网络结构的性能优势. 小样本学习
通过从表 2 中的类别随机选择标记样本作为支持集, 并从每类中选取剩余的一部分作为查询集, 支持集与查询集
分别用作网络的输入和输出前评估的样本. 支持集和查询集的排列组合可以有效缓解数据样本稀疏和不平衡问
题, 以及需求冷启动问题. 在网络构造上, 网络结构由编码器, 归纳模块和关系模块堆叠构成, 用以捕捉文本中隐含
的时序逻辑语义信息. 编码器使用 LSTM 以增加对长文本语义的理解能力, 在归纳模块应用动态路由算法, 共享
样本特征信息, 提升输出和真实预测结果的耦合系数. 在与多种多分类神经网络模型对比下, 观察到 FSLNets-
TLSA 的性能表现如表 6 所示.
根据表 6 实验结果, 本文可以更直观地观察各个模型在不同指标上的表现差异. FSLNets-TLSA 模型在损失函
数、精确度、召回率和 F1 值上都优于其他模型. 具体而言, FSLNets-TLSA 模型在损失函数上具有最低值 0.24,
损失函数的值越低, 表示模型对训练数据的拟合越好, 从而反映了本模型在预测时的高准确性和在训练学习过程
中的高效性. 相比之下, FastText、CNN、RNN、SANN 和 GPT-4 模型的损失值较高, HAN 模型的损失值是最高
的. 其原因为, 对比模型的网络结构不适用于捕捉需求文本中的关键时序和逻辑特征信息, 同时这些模型也未对数