
Page 67 - 《软件学报》2025年第12期
P. 67
5448 软件学报 2025 年第 36 卷第 12 期
• Amazon S3 REST API 是基于 REST 架构设计的云存储和检索数据的网络服务接口, 该 API 允许用户以编
程方式管理 Amazon S3 中储存数据, 包括上传和下载文件、创建和删除存储桶, 以及管理存储桶中的对象.
• PayPal Payment REST API 是 PayPal 提供的一组用于处理支付交易的编程接口, 该 API 通过 HTTP 请求和
JSON 格式的数据进行通信. 它允许开发者集成 PayPal 支付功能到其应用、网站或服务中, 从而实现在线购物、
捐赠和其他支付相关的功能.
• Java.Io 是 Java 编程语言中用于处理输入和输出操作的标准 I/O 库, 此库提供了一组类和接口, 用于与文件、
流和其他输入/输出资源进行交互, 主要涉及字符和字节级别的 I/O, 包括文件读写、网络操作、标准输入输出等.
训练集、测试集和验证集的划分比例为 6:2:2, 这种划分比例确保了在小样本学习提供足够的测试和验证数
据, 以有效评估和调整模型. 数据集标注情况如表 3 所示.
表 3 数据标注实例
标记信息 训练集 测试集/验证集 自然语言句子示例
sometimes (♢) 315 105 If an I/O error occurs
always (□) 477 158 If bMM is null, a NullPointerExceptionMM is thrown
next () 163 54 The first byte read is stored into element b[off]MM, the next one into b[off+1]MM, and so on
implication (→) 1 576 525 All objects added to the bucket receive the version ID null
prj 118 42 Schedules the specified task for repeated fixed-rate execution, beginning at the specified time
本文实验环境是一台装有 Ubuntu 22.04.4 LTS 操作系统的主机, CPU 为 Intel(R) Core(TM) i9-14900K, 内存大
小为 128 GB, 存储大小为 2 TB 的固态硬盘, 显卡为 NVIDIA GeForce RTX 4090 显卡. 实验设定 LSTM 的隐藏状
态大小为 128, 注意力维度为 64. 动态路由算法使用的迭代次数为 3, 关系模块是一个 120 维度的神经层.
4.2 实验验证
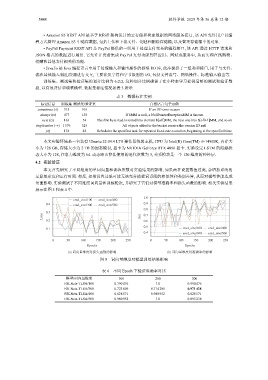
本文首先研究了不同维度的单词向量和训练次数对实验结果的影响, 如果两者设置数值过高, 会增加系统的
运算复杂度和运行时间. 相反, 如果设置过低可能无法充分捕捉词语间的相似性和类别差异, 从而对模型性能造成
负面影响. 实验测试了不同维度词向量和训练轮次, 并研究了它们对模型准确率和损失函数的影响. 相关实验结果
展示在图 5 和表 4 中.
1.0
emd_size/100 emd_size/400
0.4 emd_size/300 emd_size/500 0.9
0.8
0.3
Loss Acc 0.7
0.2 0.6
0.5
0.1 emd_size/100 emd_size/400
0.4 emd_size/300 emd_size/500
0 50 100 150 200 250 0 50 100 150 200 250
Epochs Epochs
(a) 词向量维度对损失函数的影响 (b) 词向量维度对准确率的影响
图 5 词向量维度对模型训练结果影响
表 4 不同 Epoch 下验证准确率对比
模型/词向量维度 100 200 300
FSLNets-TLSA/100 0.790 476 1.0 0.990 476
FSLNets-TLSA/300 0.723 809 0.714 285 0.971 428
FSLNets-TLSA/400 0.628 571 0.980 952 0.828 571
FSLNets-TLSA/500 0.980 952 1.0 0.895 238