
Page 70 - 《软件学报》2025年第12期
P. 70
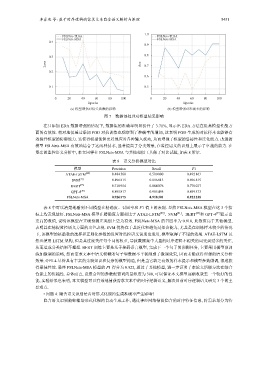
李春奕 等: 基于时序逻辑的需求文本隐含语义解析与推理 5451
1.0
FSLNets-TLSA FSLNets-TLSA
FSLNets-MSA FSLNets-MSA
0.4
0.9
0.8
0.3
Loss Acc 0.7
0.2
0.6
0.1 0.5
0 20 40 60 80 100 0 20 40 60 80 100
Epochs Epochs
(a) 模型增强对损失函数的影响 (b) 模型增强对准确率的影响
图 7 数据预处理对模型结果影响
在只添加 EDA 数据增强的情况下, 数据集的准确率明显提升了 3.71%, 显示出 EDA 方法在提高模型性能方
面的有效性. 相对地仅通过添加 PGD 对抗训练也观察到了准确率的增加, 这表明 PGD 生成的对抗样本也能够有
效提升模型的防御能力. 这使得模型能够更好地应对各种输入扰动, 从而增强了模型的鲁棒性和泛化能力. 改进的
模型 FSLNets-MSA 有效地结合了这两种技术, 显著提高了分类效果, 在监控语义的识别上展示了卓越的能力. 在
复杂的监控语义分析中, 本文同样在 FSLNets-MSA 与其他相似工具做了对比试验, 如表 8 所示.
表 8 语义分析模型对比
模型 Precision Recall F1
ATAE-LSTM [40] 0.484 568 0.500 000 0.492 163
SVM [41] 0.896 815 0.896 815 0.896 815
BERT [23] 0.718 954 0.884 076 0.776 037
GPT-4 [39] 0.895 817 0.905 495 0.899 573
FSLNets-MSA 0.926 575 0.918 301 0.922 238
表 8 中可以清楚地看到不同模型在精确度、召回率和 F1 值上的表现. 显然 FSLNets-MSA 模型在这 3 个指
标上均表现最好. FSLNets-MSA 模型在精确度方面相比于 ATAE-LSTM [40] 、SVM [41] 、BERT [23] 和 GPT-4 [39] 显示出
更高的数值, 说明该模型在正确预测正类别上更为有效. FSLNets-MSA 的召回率为 0.918, 此数值高于其他模型,
表明其在捕捉监控语义方面的出色表现. SVM 优势在于其泛化和避免过拟合能力, 尤其是在训练样本较少的情况
下, 该模型的核函数的选择和正则化参数的设置对监控语义识别也适用, 模型取得了不错的效果. ATAE-LSTM 虽
然也使用 LSTM 架构, 但是其过度关注每个词的权重, 导致数据集中大量的时序逻辑不相关的词受到过多的关注,
从而造成分类结果不理想. BERT 训练主要是基于掩码语言模型, 完成下一个句子的预测任务, 主要采用模型预训
练加微调的策略, 然而需求文本中语义模糊的句子和数据不平衡削弱了微调效果, 因而未能获得理想的语义分析
效果. GPT-4 尽管具有丰富的先验知识和复杂的模型构造, 但是当它缺乏有效的样本提示和模型参数微调, 很难获
得最佳性能. 最终 FSLNets-MSA 模型的 F1 得分为 0.922, 超过了其他模型, 进一步证明了本论文所提方法在综合
性能上的优越性. 总体而言, 设置合理的参数配置词向量维度为 300, 可以保证本文模型逐渐收敛至一个较好的性
能, 实验结果也表明, 本文模型可以有效地捕获需求文本中的时序逻辑语义, 解决目前时序逻辑语义研究 3 个的主
要难点.
• 问题 4: 隐含语义识别是否对形式化规约生成准确率产生影响?
隐含语义识别能够辅助形式化规约自动生成工作, 通过神经网络捕捉隐含的时序特征信息, 将需求划分为特