
Page 310 - 《软件学报》2025年第10期
P. 310
刘全 等: 扩散模型期望最大化的离线强化学习方法 4707
于未引入扩散模型的算法, 可见扩散模型有效地提高了算法的性能. 在训练的 20 万步前, DMEM 算法性能提升明
显快于未引入扩散模型的算法, 由此可见扩散模型还能提高算法的收敛性, 加快模型的学习效率.
表 3 不同动作权重系数的 DMEM 算法最终性能
任务 ς = 0.02 ς = 0.2 ς = 0.5 ς = 0.995
Antmaze-umaze 90.870 95.705 86.149 50.572
Antmaze-umaze-diverse 65.624 68.729 60.527 34.173
Antmaze-large-diverse 48.447 52.385 43.711 19.481
DMEM DMEM w/o diffusion
80 80 40
平均奖励 60 平均奖励 60 平均奖励
40
40
20 20 20
0 0 0
6
0 0.2 0.4 0.6 0.8 1.0 (×10 ) 0 0.2 0.4 0.6 0.8 1.0 (×10 ) 0 0.2 0.4 0.6 0.8 1.0 (×10 )
6
6
(a) Antmaze-umaze-diverse (b) Antmaze-medium-diverse (c) Antmaze-large-play
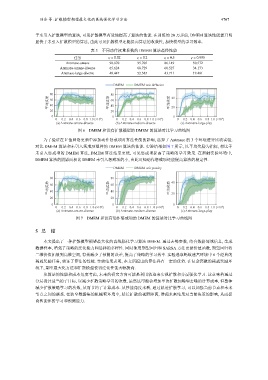
图 6 DMEM 和没有扩散模型的 DMEM 的算法对比学习曲线图
为了验证在 V 值网络更新中添加动作惩戒项对算法性能的影响, 选择了 Antmaze 的 3 个环境进行比较实验.
对比 DMEM 算法和未引入惩戒项组件的 DMEM 算法的性能. 实验结果如图 7 所示, 以平均奖励为指标, 相比于
未引入惩戒项的 DMEM 算法, DMEM 算法结果更优, 可见惩戒项提高了策略的学习效果. 在消融实验环境中,
DMEM 算法的阴影面积比 DMEM 未引入惩戒项的小, 由此可知动作惩戒项还能提高算法的稳定性.
DMEM DMEM w/o penalty
80 80 40
平均奖励 60 平均奖励 60 平均奖励
40
40
20 20 20
0 0 0
6
6
6
0 0.2 0.4 0.6 0.8 1.0 (×10 ) 0 0.2 0.4 0.6 0.8 1.0 (×10 ) 0 0.2 0.4 0.6 0.8 1.0 (×10 )
(a) Antmaze-umaze-diverse (b) Antmaze-medium-diverse (c) Antmaze-large-play
图 7 DMEM 和没有动作惩戒项的 DMEM 的算法对比学习曲线图
5 总 结
本文提出了一种扩散模型期望最大化的离线强化学习算法 DMEM. 通过去噪参数, 结合数据邻域信息, 生成
数据样本, 增强了策略的泛化能力和选择的多样性. 同时使用期望回归和 SARSA 方法更新价值函数, 期望回归将
二维价值拓展到高维空间, 有效减少了预测的误差, 提高了策略的学习效率. 实验选取蚂蚁迷宫环境中 6 个经典的
稀疏奖励任务, 验证了算法的性能. 实验结果表明, 本文所提出的算法具有一定的优势. 在复杂离散的稀疏奖励环
境下, 期望最大化方法和扩散模型使得泛化性能大幅提高.
从算法的性能和成本角度考虑, 未来的研究方向可能是利用轨迹来实现扩散和分层强化学习. 这意味着通过
分层设计适当的子目标, 以减少扩散策略学习的次数. 虽然这可能会增加单次扩散加噪和去噪的计算成本, 但整体
减少扩散策略学习的次数, 从而节约了计算成本. 从性能角度来看, 通过轨迹扩散学习, 可以加强当前节点和未来
节点之间的联系. 在狭窄数据集的机械臂环境中, 延长扩散的视野距离, 增强未来结果对当前决策的影响, 从而提
高智能体的学习和预测能力.