
Page 309 - 《软件学报》2025年第10期
P. 309
4706 软件学报 2025 年第 36 卷第 10 期
表 2 给出了 4 个算法在 6 个任务中所获得的累计回报的均值和标准偏差. 其结果是在训练 5 个种子的基础上
记录的. 其中均值和标准偏差都经过了归一化处理. 以均值作为最终评判标准, 实验图是根据均值和偏差共同绘
制. 表中加粗了任务中表现优异的实验数据. 从平均值的角度, 观察到 DEME 方法在 6 个任务中的性能, 均优于其
他算法. 但从标准偏差的角度观察, 在大部分任务中, DMEM 方法的训练过程的稳定性较好. 在 Antmaze-umaze-
diverse 和 Antmaze-large-play 中 DMEM 稳定性比 IQL 算法差. 究其原因是: 在稀疏奖励的情况下, 为了提高
DMEM 算法的泛化能力, 而牺牲了训练过程中的一部分稳定性.
表 2 DMEM 与 CQL, Diffusion-QL, IQL 离线强化学习算法最终性能对比
CQL Diffusion-QL IQL DMEM
任务
平均值 标准偏差 平均值 标准偏差 平均值 标准偏差 平均值 标准偏差
Antmaze-umaze 86.651 14.342 68.454 34.62 86.842 3.145 95.705 1.660
Antmaze-umaze-diverse 68.454 34.620 52.827 18.112 63.092 1.165 68.729 5.254
Antmaze-medium-play 63.314 17.484 –0.73 1.476 68.628 3.861 71.36 2.923
Antmaze-medium-diverse 86.842 3.145 22.212 33.041 65.502 10.724 82.97 3.689
Antmaze-large-play 30.284 11.591 10.977 11.918 36.217 1.996 44.184 5.361
Antmaze-large-diverse 41.137 11.063 3.813 7.446 44.61 6.662 52.385 1.447
在 Antmaze 任务的 6 个环境上, 根据以上实验结果, 验证了 DMEM 算法优于传统的离线强化学习算法. 下面
进一步研究该方法对重要超参数的敏感性. 价值函数是基于梯度算法更新的权重, 类似起到重要参数的作用, 其学
习的方法影响策略网络的学习. 其学习的过程, 类似于调参的过程, 在很多算法中, 重要参数对算法的性能和稳定
Q 值网络的约束, 从而有
性都有很大的影响. 在价值函数更新中添加一个惩戒项, 提高 V 值网络的学习效率, 增加
效提高算法的性能.
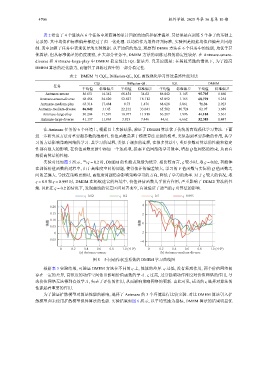
实验对比如图 5 所示, 当 ς = 0.2 时, DMEM 的性能表现最为优异. 相比较而言, ς 较小时, 取 ς = 0.02, 智能体
在训练价值函数的过程中, 由于高维度空间的问题, 使得估计的偏差较大, 学习的 V 值函数与实际的 Q 值函数之
间的差偏大. 导致在策略更新时, 高维度问题仍会影响策略学习的方向, 降低了学习的效率. 对于 ς 较大的情况, 取
ς = 0.5 和 ς = 0.995 时, DMEM 在蚂蚁迷宫的环境中, 价值评估函数几乎没有作用, 严重影响了 DEME 算法的性
能. 因此在 ς = 0.2 的情况下, 发现曲线的误差区间显著变窄, 有效验证了适当的 ς 对算法的影响.
=0.02 =0.2 =0.5 =0.995
4
0.20
0.15 2
偏差 0.10 偏差 0
0.05
0 −2
−0.05 −4
0 0.2 0.4 0.6 0.8 1.0 (×10 ) 6 0 0.2 0.4 0.6 0.8 1.0 (×10 )
6
(a) Antmaze-umaze (b) Antmaze-medium-diverse
图 5 不同动作权重系数的 DMEM 学习曲线图
根据表 3 实验结果, 可验证 DMEM 方法在不同的 ς 上, 性能的差异. ς 过低, 没有惩戒作用, 两个价值网络间
存在一定的差异, 高维度的动作空间依旧影响价值函数的学习. ς 过高, 过分强调动作维度对价值网络的作用, 导
致价值网络无法得到有效学习, 失去了评估的作用, 从而影响策略网络的更新. 由此可见, 适当的 ς 选择对算法的
性能起着重要的作用.
为了验证扩散模型对算法性能的影响, 选择了 Antmaze 的 3 个环境进行比较实验. 对比 DMEM 算法引入扩
散模型和未使用扩散模型组件算法的性能. 实验结果如图 6 所示, 以平均奖励为指标, DMEM 算法的结果明显优