
Page 308 - 《软件学报》2025年第10期
P. 308
刘全 等: 扩散模型期望最大化的离线强化学习方法 4705
目标位置都随机选择. 则蚂蚁迷宫有 6 个子环境. 其行动空间维度为 8, 意味着铰链关节有 8 个, 而动作代表在
关节处的转矩, 大小在−1 到 1 之间. 在不考虑外部接触力的情况下, 空间维度是 27. 智能体使用不同部位铰链,
采取不同的动作. 在空间维度上相比于 Maze2D 多了 8 个自由度, 将二维平面空间上升到三维, 使得任务更加
复杂.
4.2 实验设置
所有算法的每个任务, 都选取了 5 个不同的随机种子, 且都独立运行. 每个任务每次实验都要运行 100 万步,
每 5 万步评估 100 步作为估计值. 实验图中的实线是算法 5 次独立训练的平均性能结果. 实线周围的阴影则是训
练的误差范围. 阴影的范围则代表算法训练的稳定性, 范围越大稳定性越差.
DMEM 算法包含扩散策略网络和评论家网络. 扩散策略中包含加噪过程和去噪过程, 其中加噪过程不涉及网
络参数. 去噪过程中有 4 层线性神经网络, 均采用 Mish 函数作为激活函数. 其中需要将时间编码到神经网络中, 使
用正弦时间戳嵌入块 SinusoidalPosEmb 函数保留当前时间信息, 再经过两层线性神经网络, 一次 Mish 函数激活.
评论家网络包含 3 层隐藏的线性神经网络, 均采用 ReLU 作为激活函数. 策略网络和评论家网络都使用 Adam 作
为优化器, 以梯度下降的方式更新网络参数. DMEM 算法的其他超参数设置, 如表 1 所示.
表 1 DMEM 超参数设置
超参数 取值 参数描述 超参数 取值 参数描述
D 5 000 经验池大小 κ s 1E–4 时间步截断参数下线
δ 1 10 价值函数权重 κ e 2E–2 时间步截断参数上线
δ 2 10 去噪误差权重 l 3E–4 学习率
n t 5 扩散模型时间步个数 τ 5E–3 目标平滑系数
ς 0.2 更新值函数V(s)的动作权重 ω 0.7 期望回归权重
4.3 实验结果与分析
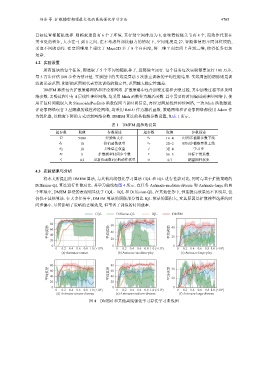
将本文所提出的 DMEM 算法, 与其他离线强化学习算法 CQL 和 IQL 进行性能对比, 同时与基于扩散策略的
Diffusion-QL 算法进行性能对比. 其学习曲线如图 4 所示. 在任务 Antmaze-medium-diverse 和 Antmaze-large 的两
个环境中, DMEM 算法的表现明显优于 CQL、IQL 和 Diffusion-QL. 在其他任务中, 性能提高效果虽不甚明显, 但
仍优于其他算法. 在大多任务中, DMEM 算法的阴影部分都比 IQL 算法的面积大, 究其原因是扩散模型选择的时
间步偏小. 尽管影响了策略的去噪效果, 但节省了训练的时间成本.
CQL Diffusion-QL IQL DMEM
80 40
平均奖励 60 平均奖励 60 平均奖励
40
40
20 20 20
0 0 0
6
6
6
0 0.2 0.4 0.6 0.8 1.0 (×10 ) 0 0.2 0.4 0.6 0.8 1.0 (×10 ) 0 0.2 0.4 0.6 0.8 1.0 (×10 )
(a) Antmaze-umaze (b) Antmaze-medium-play (c) Antmaze-large-play
80 80 40
平均奖励 60 平均奖励 60 平均奖励 20
40
40
20 20
0 0 0
6
6
0 0.2 0.4 0.6 0.8 1.0 (×10 ) 6 0 0.2 0.4 0.6 0.8 1.0 (×10 ) 0 0.2 0.4 0.6 0.8 1.0 (×10 )
(d) Antmaze-umaze-diverse (e) Antmaze-medium-diverse (f) Antmaze-large-diverse
图 4 DMEM 和其他离线强化学习算法学习曲线图