
Page 216 - 《软件学报》2025年第9期
P. 216
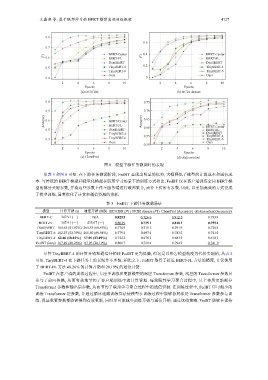
王鑫澳 等: 基于联邦学习的 BERT 模型高效训练框架 4127
0.8
0.6
0.7
F1 0.6 BERT-Center F1 0.4 BERT-Center
BERT-FL
BERT-FL
DistilBERT DistilBERT
0.5 TinyBERT-4 0.2 TinyBERT-4
TinyBERT-6 TinyBERT-6
Ours Ours
0.4 0
2 4 6 8 10 2 4 6 8 10
Epochs Epochs
(a) BC5CDR (b) NCBI disease
0.8 0.75
0.7 0.70
Accuracy 0.6 BERT-Center Accuracy 0.65
BERT-FL
0.5 DistilBERT 0.60 BERT-Center
BERT-FL
TinyBERT-4 DistilBERT
0.55 TinyBERT-4
0.4 TinyBERT-6 TinyBERT-6
Ours Ours
0.50
2 4 6 8 10 2 4 6 8 10
Epochs Epochs
(c) ChemProt (d) citation intent
图 8 模型下游任务微调时的表现
从表 3 和图 8 可知, 在下游任务微调阶段, FedBT 显现出明显的优势, 大幅降低了模型的计算成本和通信成
本. 与传统的 BERT 模型和轻量化模型在联邦学习场景下的训练方式相比, FedBT 仅在客户端训练全局 BERT 模
型的部分关键参数, 并将这些参数上传至服务端进行联邦聚合, 而非上传所有参数. 因此, 以更加高效的方式完成
了模型训练, 显著优化了计算和通信资源的消耗.
表 3 FedBT 下游任务微调场景
模型 计算开销 (s) 通信开销 (MB) BC5CDR (F1) NCBI disease (F1) ChemProt (Accuracy) citation intent (Accuracy)
BERT-C 347.91 (-) N/A 0.825 5 0.726 6 0.812 3 0.733 8
BERT-FL 347.91 (-) 435.67 (-) 0.803 9 0.735 1 0.818 1 0.755 4
DistilBERT 180.63 (51.92%) 265.53 (60.95%) 0.778 9 0.711 1 0.791 9 0.726 6
TinyBERT-6 182.27 (52.39%) 265.50 (60.94%) 0.779 2 0.697 4 0.783 2 0.741 0
TinyBERT-4 62.66 (18.01%) 57.05 (13.09%) 0.752 2 0.678 1 0.683 5 0.618 7
FedBT (ours) 167.89 (48.26%) 87.95 (20.19%) 0.806 7 0.721 4 0.794 2 0.741 0
尽管 TinyBERT-4 的计算开销和通信开销较 FedBT 更为低廉, 但这是以损害模型精度为代价实现的, 从表 2
可知, TinyBERT-4 在下游任务上的表现并不理想, 相比之下, FedBT 取得了接近 BERT-FL 方法的精度, 且仅使用
了 BERT-FL 方法 48.26% 的计算开销和 20.19% 的通信开销.
FedBT 在客户端的训练过程中, 专注于训练和更新模型的深层 Transformer 参数, 浅层的 Transformer 参数只
参与了前向传播, 从而有效地节约了客户端训练中的计算资源. 每轮联邦学习聚合过程中, 只上传所更新部分
Transformer 参数和输出层参数, 从而节约了联邦学习聚合过程中的通信资源. 在训练过程中, FedBT 尽可能少的
训练 Transformer 层参数, 并通过循环递减训练算法使模型在训练过程中能够协同深层 Transformer 参数参与训
练, 保证重要参数都能够得到有效更新, 同时尽可能减少训练开销与通信开销. 通过这些策略, FedBT 能够在保持