
Page 214 - 《软件学报》2025年第9期
P. 214
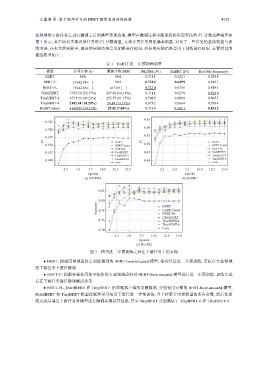
王鑫澳 等: 基于联邦学习的 BERT 模型高效训练框架 4125
业领域的下游任务上进行微调之后的模型表现效果, 模型在微调过程中随训练轮次而变化的 F1 分数或准确率如
图 7 所示, 其中命名实体识别任务用 F1 分数衡量, 文本分类任务用准确率衡量. 对比了一些常见的基线模型与训
练方法, 在本文的实验中, 最好的实验结果会用加粗进行标识, 次好的实验结果会用下划线进行标识. 主要对比的
基线模型如下.
表 1 FedBT 进一步预训练场景
模型 计算开销 (s) 通信开销 (MB) JNLPBA (F1) SciERC (F1) Rct-20k (Accuracy)
BERT N/A N/A 0.718 1 0.622 3 0.824 8
BERT-C 13 642.88 (-) N/A 0.724 4 0.649 9 0.812 1
BERT-FL 13 642.88 (-) 417.83 (-) 0.722 4 0.633 0 0.818 5
DistilBERT 7 553.50 (55.37%) 267.98 (64.14%) 0.711 1 0.627 8 0.828 0
TinyBERT-6 6 715.92 (49.23%) 255.57 (61.17%) 0.708 5 0.608 9 0.807 3
TinyBERT-4 2 482.41 (18.20%) 54.88 (13.13%) 0.673 2 0.566 4 0.799 4
FedBT (ours) 4 680.99 (34.31%) 29.42 (7.04%) 0.719 8 0.642 1 0.831 2
0.65
0.725
0.60
0.700
0.55
0.675
F1 BERT F1 BERT
0.650 BERT-Center 0.50 BERT-Center
BERT-FL BERT-FL
0.625 DistilBERT 0.45 DistilBERT
TinyBERT-4 TinyBERT-4
0.600 TinyBERT-6 0.40 TinyBERT-6
Ours Ours
2.5 5.0 7.5 10.0 12.5 15.0 2.5 5.0 7.5 10.0 12.5 15.0
Epochs Epochs
(a) JNLPBA (b) SciERC
0.82
0.80
Accuracy 0.78 BERT
BERT-Center
BERT-FL
DistilBERT
0.76 TinyBERT-4
TinyBERT-6
Ours
0.74
2.5 5.0 7.5 10.0 12.5 15.0
Epochs
(c) Rct-20k
图 7 模型进一步预训练之后在下游任务上的表现
● BERT: 指通用领域语料上训练得到的 BERT-base-uncased 模型, 没有经过进一步预训练, 直接在专业领域
的下游任务上进行微调.
● BERT-C: 指服务端使用集中收集的专业领域语料对 BERT-base-uncased 模型进行进一步预训练, 训练完成
后在下游任务进行微调测试效果.
● BERT-FL, DistilBERT 和 TinyBERT: 指忽略客户端的资源限制, 分别使用完整的 BERT-base-uncased 模型,
DistilBERT 和 TinyBERT 模型在联邦学习场景下进行进一步预训练, 并上传聚合更新模型的所有参数, 然后在训
练完成后通过下游任务对模型进行微调并测试其性能, 其中 TinyBERT 分别测试了 TinyBERT-6 和 TinyBERT-4.