
Page 477 - 《软件学报》2025年第5期
P. 477
苏浩然 等: SPARC 架构下低时延微内核进程间通信设计 2377
的寄存器传参机制.
4.3 系统服务测试
微内核上的应用程序大量使用 IPC 的场景一般情况下主要是用于调用系统服务, 比如文件系统、网络服务
等, 应用程序在调用文件系统接口时都会向用户态运行的文件系统服务发送 IPC 请求, 于是我们使用在 ChCore
上实现的内存文件系统 tmpfs, 测试了应用程序文件操作的性能. 我们测试了测试程序调用一些经典的文件系统接
口时的性能, 比较了优化前 (Base) 以及采用 BankedIPC 方法优化后 (Optimized) 的性能, 以吞吐率作为衡量指标,
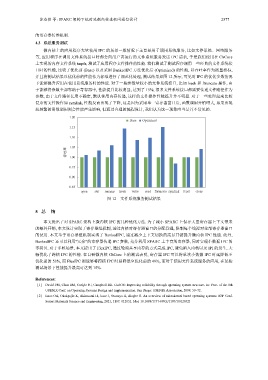
并且将测试结果以优化前的性能作为标准进行了规范化处理, 测试结果如图 12 所示, 可见对 IPC 的优化多数情况
下能够提升应用在使用系统服务时的性能. 对于一些参数量较小的文件系统接口, 比如 lseek 和 ftruncate 操作, 由
于能够将参数全部容纳于寄存器中, 性能提升比较明显, 达到了 15%; 很多文件系统接口都需要传递文件路径作为
参数, 由于文件路径长度不确定, 默认使用内存传递, 这样的文件操作性能提升并不明显. 对于一些处理起来比较
复杂的文件操作如 symlink, 性能反而出现了下降, 这是因为采用单一寄存器窗口后, 函数调用开销增大, 如果出现
较频繁的函数调用则会性能产生影响, 但通过合理的编程设计, 我们认为这一现象应当是并不常见的.
1.20
Base Optimized
1.15
1.10
吞吐率 1.05
1.00
0.95
0.90
0.85
open stat rename lseek write read ftruncate symlink fcntl close
图 12 文件系统服务测试结果
5 总 结
本文提出了对 SPARC 架构上微内核 IPC 的几种优化方法. 为了减小 SPARC 上保存大量寄存器上下文带来
的额外开销, 本文设计实现了寄存器组机制, 通过内核对寄存器窗口的分配管理, 限制每个线程对全部寄存器窗口
的使用. 本文基于寄存器组机制实现了 BankedIPC, 通过减少上下文切换的高昂开销提升微内核 IPC 性能. 此外,
BankedIPC 还可以利用“冗余”的寄存器传递 IPC 参数, 充分利用 SPARC 上丰富的寄存器, 同时实现小数据 IPC 的
零拷贝. 对于多核场景, 本文提出了 FlexIPC, 通过轮询共享内存的方式完成 IPC, 避免陷入内核以及 IPI 的发生, 大
幅优化了跨核 IPC 的性能. 在自研微内核 ChCore 上的测试表明, 寄存器 IPC 可以将单次小数据 IPC 时延降低至
优化前的 53%, 而 FlexIPC 则能够将跨核 IPC 时延降低至优化前的 49%, 而对于使用文件系统服务的应用, 在某些
测试场景下性能提升最高可达到 15%.
References:
[1] David FM, Chan EM, Carlyle JC, Campbell RH. CuriOS: Improving reliability through operating system structure. In: Proc. of the 8th
USENIX Conf. on Operating Systems Design and Implementation. San Diego: USENIX Association, 2008. 59–72.
[2] Isaac OA, Okokpujie K, Akinwumi H, Juwe J, Otunuya H, Alagbe O. An overview of microkernel based operating systems. IOP Conf.
Series: Materials Science and Engineering, 2021, 1107: 012052. [doi: 10.1088/1757-899X/1107/1/012052]