
Page 474 - 《软件学报》2025年第5期
P. 474
2374 软件学报 2025 年第 36 卷第 5 期
优化目标. 而 SPARC 架构的寄存器数量较多以及 IPI 性能较差这两个特性是与架构设计相关的, 因此虽然我们目
前仅在 ChCore 上进行了测试, 但本文优化 IPC 的方法在其他 SPARC 架构的微内核上也是可行的.
4.2 微基准测试
在本小节中, 我们希望通过微基准测试回答以下问题.
• RQ1: BankedIPC 能对 ChCore 上的单核 IPC 性能带来多少提升?
• RQ2: BankedIPC 提升 IPC 性能的原理是什么?
• RQ3: 内核采用的寄存器组机制能否对非 IPC 场景带来优化效果? 是否存在局限性?
• RQ4: FlexIPC 能对 ChCore 上的跨核 IPC 性能带来多少提升?
(1) RQ1: BankedIPC 能对 ChCore 上的单核 IPC 性能带来多少提升?
为了说明 BankedIPC 对 ChCore 上 IPC 的优化效果, 我们对优化前后单次 IPC 的平均时延进行了测试. 我们
创建了两个测试进程作为 IPC 客户端和服务端, 客户端则创建多个线程同时向服务端发送一定数量的并发 IPC 请
求, 对于每个被测试的 IPC 并发数量, 我们运行了 3 次上述测试并取平均值, 得到每次 IPC 的平均时延. 我们测试
了两种不同类型的 IPC, 一种是零数据 IPC, 即客户端不通过 IPC 传输任何数据, 服务端接收到 IPC 请求后也不会
进行任何处理, 而是直接返回, 测试这种 IPC 可以使我们重点关注到 IPC 控制流转移的性能; 另一种测试类型是
传输少量数据的 IPC, 客户端会传输大小为 20 B 的数据, 服务端会读取这些数据并进行简单处理, 并将处理结果
返回, 这一数据量足以容纳于寄存器中, 进行此测试的目的是比较使用寄存器传递数据和共享内存传递数据的性
能. 我们在 ChCore 上分别测试了未优化 (Base) 和采用 BankedIPC 优化后的两种 IPC 在上述两种场景下的性能.
为了避免跨核 IPC 带来的额外影响, 本测试中每个 IPC 客户端线程和服务端线程都位于同一个处理器核心上. 测
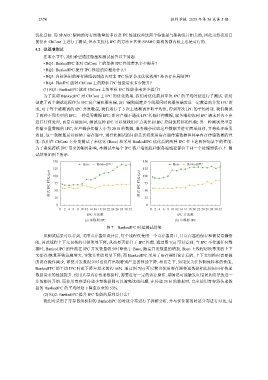
试结果如图 7 所示.
150 150
Base BankedIPC Base BankedIPC
125 125
单次 IPC 时延 (μs) 75 单次 IPC 时延 (μs) 75
100
100
50
50
25 25
0 0
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32
IPC 并发数 IPC 并发数
(a) 零数据 IPC (b) 小数据 IPC
图 7 BankedIPC 时延测试结果
从测试结果可以看到, 采用寄存器组设计后, 每个线程仅使用一个寄存器窗口, 且寄存器的保存和恢复是懒惰
的, 因此线程上下文切换的开销明显下降, 从而显著提升了 IPC 性能. 通过图 7(a) 可以看到, 当 IPC 不传递任何数
据时, BankedIPC 的性能在 IPC 并发数量较少时略优于 Base, 随着并发数量的增加, Base 上线程切换带来的上下
文保存/恢复开销急剧增大, 导致其性能明显下降; 而 BankedIPC 采用了寄存器组设计后的, 上下文切换时需要做
的访存操作减少, 即使并发数很多时也没有出现特别严重的性能下降. 相比之下, 如果仅关注控制流转移的性能,
BankedIPC 的平均 IPC 时延下降至原来的约 66%. 通过图 7(b) 可以看出使用寄存器传递数据相比使用内存传递
数据带来的性能提升. 使用共享内存传递数据时, 需要进行一定的访存操作, 期间还可能触发页错误从而导致进一
步的额外开销. 而使用寄存器传递少量数据则可以避免这些问题, 在传递 20 B 的数据时, 完全使用寄存器传递数
据的 BankedIPC 的平均时延下降至原来的 53%.
(2) RQ2: BankedIPC 提升 IPC 性能的原理是什么?
我们对采用了寄存器组机制的 BankedIPC 的时延分布进行了拆解分析, 并与优化前的时延分布进行对比, 结