
Page 475 - 《软件学报》2025年第5期
P. 475
苏浩然 等: SPARC 架构下低时延微内核进程间通信设计 2375
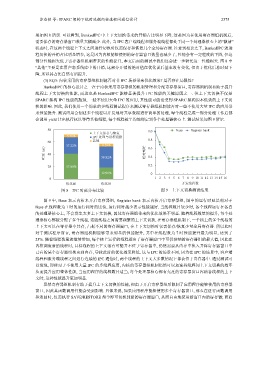
果如图 8 所示. 可以看到, BankedIPC 中上下文切换带来的开销占比明显下降, 这是因为在使用寄存器组机制后,
需要保存的寄存器窗口数量大幅减少. 此外, 当 IPC 客户端线程和服务端线程都处于同一个处理器核心上的“激活”
状态时, 在这两个线程上下文之间进行切换时仅需保存和恢复几个全局寄存器. 注意到相比之下, BankedIPC 的进
程切换的开销占比明显增多, 这是因为内核能够使用的寄存器窗口数量也减少了, 性能会有一定程度的下降, 但这
部分性能损失低于寄存器组机制带来的性能提升, 本文后面的测试中我们还会进一步研究这一性能损失. 图 8 中
“其他”主要是在用户态系统库中的开销, 这部分开销的绝对值在优化前后基本没有变化, 但由于优化后总时延下
降, 所以其占比自然有所提升.
(3) RQ3: 内核采用的寄存器组机制能否对非 IPC 场景带来优化效果? 是否存在局限性?
BankedIPC 的核心设计之一在于内核采用寄存器组的机制管理和分配寄存器窗口, 寄存器组机制有助于提升
线程上下文切换的性能, 而这也是 BankedIPC 能够显著提升 IPC 性能的关键原因之一. 但上下文切换不仅是
SPARC 架构 IPC 性能的瓶颈, 一些不使用大量 IPC 的应用, 其性能可能也受到 SPARC 架构原本低效的上下文切
换的影响. 因此, 我们使用一个简单的多线程测试程序来测试寄存器组机制能否对一些不使用大量 IPC 的应用带
来性能提升. 测试应用会创建多个线程以并发地对共享数据进行简单的处理, 每个线程完成一部分处理工作后都
会调用 yield 让出执行权以等待其他线程, 每个线程被平均地绑定到各个处理器核心上. 测试结果如图 9 所示.
80 1.0 Base Register bank
上下文保存与恢复
5.78% IPC 处理与进程切换
其他 0.8
60
37.22% 8.28% 0.6
时延 (μs) 40 58.82% 相对耗时 0.4
0.2
20 57.00%
32.91% 0
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
优化前 优化后 并发线程数
图 8 IPC 时延分布比较 图 9 上下文切换测试结果
图 9 中, Base 表示内核未开启寄存器组, Register bank 表示内核开启寄存器组, 图中的运行时延是相对于
Base 在线程数为 1 时的运行耗时的比值, 运行耗时越少表示性能越好. 当线程数目较少时, 各个线程运行在各自
的处理器核心上, 不会发生太多上下文切换, 因此寄存器组带来的优化效果不明显. 随着线程数量的提升, 每个处
理器核心都被分配了多个线程, 这些线程之间需要频繁的上下文切换, 在寄存器组机制下, 一个核上的多个线程的
上下文可以在寄存器中共存, 占据不同的寄存器窗口, 在上下文切换时仅需保存/恢复少量全局寄存器. 所以此时
对于测试程序而言, 寄存器组机制能够带来明显的性能提升, 其中在线程数为 7 时性能提升最为明显, 达到了
23%. 随着线程数量的继续增加, 每个核上运行的线程超出了寄存器窗口中可供容纳的寄存器组的最大值, 因此在
内核调度新的线程时, 目标线程的上下文很有可能并不位于寄存器中, 仍然需要从内存中换入并将寄存器窗口中
已有的某个寄存器组换出到内存, 导致此时的优化效果降低. 这与 IPC 的场景不同, 因为在 IPC 的场景中, 客户端
线程和服务端线程之间进行连续的 IPC 通信时, 两个线程的上下文大多数情况下都会位于寄存器中. 通过测试可
以发现, 即使对于不使用大量 IPC 的多线程应用, 内核的寄存器组机制仍然可以加速其线程间上下文切换的效率
从而提升应用整体性能, 当应用程序的线程数目适当, 每个处理器核心都有充足的寄存器窗口容纳各线程的上下
文时, 这种性能提升更加明显.
虽然寄存器组机制有助于提升上下文切换的性能, 但由于开启寄存器组后限制了应用程序能够使用的寄存器
窗口, 因此其函数调用性能会受到影响. 具体来说, 如果应用程序能够使用多个寄存器窗口, 那么在进行函数调用
和返回时, 仅需执行 SAVE/RESTORE 指令即可切换到新的寄存器窗口, 从而自由地使用新窗口内的寄存器; 而启