
Page 362 - 《软件学报》2021年第12期
P. 362
4026 Journal of Software 软件学报 Vol.32, No.12, December 2021
Key words: video-based person re-identification; neighborhood center iteration strategy; label evaluation method; one-shot; loss control
strategy
行人重识别(person re-identification)旨在解决跨摄像机检索匹配行人图像或视频的问题,主要有两种方法:
基于图像的行人重识别和基于视频的行人重识别.前者利用行人图像匹配同一行人在不同摄像机视图下的行
人图像 [1−5] ,后者直接利用信息更加丰富的行人视频片段匹配同一行人在不同摄像机视图下的行人视频 [6−8] .而
基于视频的行人重识别与现实世界的应用更为贴切,从而在近期引起了极大的关注.现有的基于视频的行人重
识别的方法主要依赖于完全标注的视频片段.由于标注数据的成本过于巨大,因此研究依赖少量标注的半监督
视频行人重识别具有极大的应用价值.
单标注样本学习是半监督学习的一种.单标注样本视频行人重识别的关键在于如何准确地对大量无标签
视频片段进行标签估计 [9−11] .其常见的方法是:在迭代过程中先将数据嵌入特征空间,以每个行人唯一的有标签
视频片段特征作为固定度量中心,无标签视频片段根据与固定度量中心的距离为其分配伪标签.初始有标签数
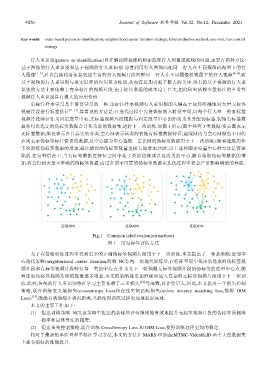
据和每次选定的伪标签数据合并作为新的数据集,进行下一次训练.如图 1 所示(图中共有 3 类数据:实心圆表示
无标签数据,颜色表示各自真实的分类;空心圆表示该类的初始有标签数据特征;虚线圆内与空心圆颜色不同的
点则表示伪标签标注错误的数据,以空心圆为中心选取一定比例的伪标签数据用于下一次训练):随着选取用作
下次训练伪标签数据的增加,标注错误的伪标签数量也极大地增加.因此,以上这种固定度量中心的方法是有缺
陷的.在这种情况下,当有标签数据在特征空间中处于类的边缘或者远离类的中心,随着选取伪标签数据的增
加,将会得到大量不准确的伪标签数据,而过多的不可靠的伪标签数据在迭代过程中将会严重影响模型的性能.
选取20% 选取40% 选取80%
Fig.1 Common label evaluation methods
图 1 常见标签评估方式
为了在每轮训练过程中得到更多的正确伪标签视频片段用于下一次训练,本文提出了一种新策略:近邻中
心迭代策略(neighborhood center iteration,简称 NCI).每一次迭代训练后,在特征空间中找出所选取的伪标签视
频片段和有标签视频片段特征每一类的中心点,作为其下一轮预测无标签视频片段的伪标签的度量中心点.随
着选取伪标签视频片段的数量逐步增加,本文的策略能更加准确地加入复杂的无标签视频片段用于下一次训
练.此外,传统的行人重识别特征学习主要依赖于三重损失 [12] 等函数,其计算量大,因此,本文提出一个损失控制
策略,联合训练交叉熵损失(crossentropy loss)和在线实例匹配损失(online instance matching loss,简称 OIM
Loss) [13] ,既能有效地缩小类内距离,又能使得训练过程更加地稳定高效.
本文的主要工作如下:
(1) 提出训练策略 NCI,该策略中提出的新标签评估准则能有效地提升无标签视频片段的伪标签预测准
确率和最终算法的精度;
(2) 提出损失控制策略,联合训练 CrossEntropy Loss 和 OIM Loss,使得训练过程更加的稳定.
相对于最新的半监督和单标注学习方法,本文的方法在 MARS 和 DukeMTMC-VideoReID 两个大型数据集
上都有很好的性能提升.