
Page 365 - 《软件学报》2021年第12期
P. 365
张云鹏 等:邻中心迭代策略的单标注视频行人重识别 4029
其中,R k 表示第 k 类样本新的度量中心点,D k 表示D中第 k 类样本的集合,N 为D k 中元素的个数.
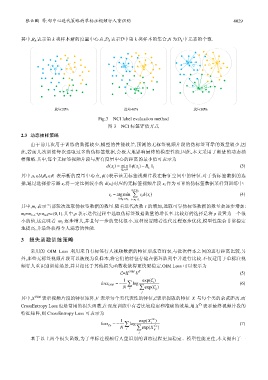
Fig.3 NCI label evaluation method
图 3 NCI 标签评估方式
2.3 动态抽样策略
由于前几次用于训练的数据较少,模型的性能较差,预测的无标签视频片段的伪标签可靠的数量较少,因
此,若前几次训练每次选取过多的伪标签数据,会极大地影响最终的模型性能.因此,本文采用了渐进的动态抽
样策略.其中,每个无标签视频片段与所有度量中心的距离的最小值可表示为
() =
dx i min || ( )xφ i − R k || 2 (3)
k R ∈ R
其中,x i ∈U,R k ∈R 表示新的度量中心点,φ(⋅)表示该无标签视频片段在特征空间中的特征.对于伪标签数据的选
择,通过选择指示器 s t 将一定比例较小的 d(x i )对应的无标签视频片段 x i 作为可靠的伪标签数据采样到训练中:
l n + u n
s = argmin ∑ sd ( )x i (4)
i
t
||s 0 || = t m in l + 1
=
其中,m t 表示当前轮次选取伪标签数据的数量.随着迭代次数 t 的增加,选取可靠伪标签数据的数量会逐步增加:
m t =m t−1 +p⋅n u ,p∈(0,1).其中,p 表示迭代过程中选取伪标签数据数量的增长率.比较好的选择是将 p 设置为一个很
小的值,这意味着 m t 逐步增大,并且每一步的变化很小.这种设置随着迭代过程逐步优化,模型性能会非常稳定
地提高,并最终获得令人满意的性能.
3 损失函数训练策略
常用的 OIM Loss 利用来自有标签行人视频数据的特征形成查询表,与批次样本之间的进行距离比较.另
外,那些无标签视频片段可以被视为负样本,将它们的特征存储在循环队列中并进行比较.不仅适用于单标注视
频行人重识别训练场景,并且相比于其他损失函数收敛得更快更稳定.OIM Loss 可以表示为
C=X OIM ⋅V T (5)
1
loss OIM =− ∑ log exp( )C i (6)
N i ∑ exp( )C ij
j
其中,X OIM 表示视频片段的特征矩阵,V 表示每个类代表性的特征,C表示提取的特征 X 与每个类的余弦距离.而
Ce
CrossEntropy Loss 也是常用的损失函数,在深度训练中有着比较稳定和准确的效果.用 X 表示最终视频片段的
特征矩阵,则 CrossEntropy Loss 可表示为
1
loss =− ∑ log exp(X i Ce ) (7)
Ce N i ∑ exp(X Ce )
j ij
基于以上两个损失函数,为了单标注视频行人重识别的训练过程更加稳定、模型性能更佳,本文提出了一