
Page 172 - 《软件学报》2021年第9期
P. 172
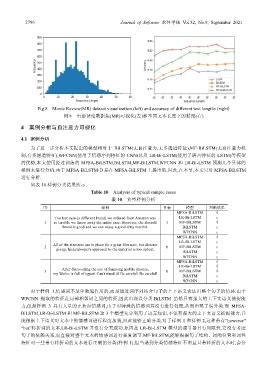
2796 Journal of Software 软件学报 Vol.32, No.9, September 2021
Fig.8 Movie Review(MR) dataset visualization (left) and accuracy of different text lengths (right)
图 8 电影评论数据集(MR)可视化(左)和不同文本长度下的精度(右)
4 案例分析与自注意力可视化
4.1 案例分析
为了进一步分析本文提出的模型相对于 BiLSTM(无自注意力,无多通道特征),MF-BiLSTM(无自注意力机
制,有多通道特征),WFCNN(使用了情感序列特征的 CNN)以及 LR-Bi-LSTM(使用了语言特征的 LSTM)等模型
的优势,本文使用经过训练的 MFSA-BiLSTM,BiLSTM,MF-BiLSTM,WFCNN 和 LR-Bi-LSTM 预测几个具体的
样例来进行分析.由于 MFSA-BiLSTM-D 是在 MFSA-BiLSTM 上提出的,因此,在本节,本文只对 MFSA-BiLSTM
进行分析.
如表 10 样例分类结果所示.
Table 10 Analysis of typical sample cases
表 10 典型样例分析
ID 样例 目标 模型 判断结果
MFSA-BiLSTM √
The last case (a different brand) we ordered from Amazon was LR-Bi-LSTM ×
1 so terrible we threw away the entire case. However, the Boscoli 1 MF-BiLSTM √
brand is good and we can enjoy a good dirty martini. BiLSTM ×
WFCNN ×
MFSA-BiLSTM √
LR-Bi-LSTM ×
All of the elements are in place for a great film noir, but director
2 0 MF-BiLSTM ×
george hickenlooper's approach to the material is too upbeat.
BiLSTM ×
WFCNN ×
MFSA-BiLSTM √
LR-Bi-LSTM √
After discovering the use of Samsung mobile phones,
3 0 MF-BiLSTM √
my Weibo is full of typos! Can't stand it! Be careful! Be careful!
BiLSTM ×
WFCNN ×
对于样例 3,情感词不是单独起作用的,而是通过词序列结合句子的上下语义表达出整个句子的情感.由于
WFCNN 提取的特征是局部相邻词之间的特征,因此出现误分类.BiLSTM 虽然具有强大的上下文语义捕捉能
力,但是样例 3 具有大量的正负面情感词,由于对特殊的情感词并没有进行处理,从而出现了误分类.而 MFSA-
BiLSTM,LR-Bi-LSTM 和 MF-BiLSTM 这 3 个模型充分利用了语言知识,不仅有强大的上下文语义捕捉能力,并
能根据上下语义对文本中的情感词进行程度加强,因此能够正确分类.对于样例 1 和样例 2,这种带有“however”
“but”转折词的文本,LR-Bi-LSTM 并没有分类成功.原因是 LR-Bi-LSTM 模型的调节器具有局限性,它没有考虑
句子的依赖关系,而直接对整个文本的情感词进行强度调节.MF-BiLSTM,能够根据句子结构、词的位置和词性
特征对一些带有转折词的文本进行正确的分类(样例 1),但当遇到分类情感特征不明显且带转折的文本时,会分