
Page 173 - 《软件学报》2021年第9期
P. 173
李卫疆 等:基于多通道特征和自注意力的情感分类方法 2797
类错误(样例 2).而本文提出的 MFSA-BiLSTM 在 MF-BiLSTM 模型上增加了自注意力,通过自注意加权,加强文
本中的情感,使情感特征信息特征更加突出.因此,本文提出的 MFSA-BiLSTM 模型可以分类成功.
4.2 自注意力可视化
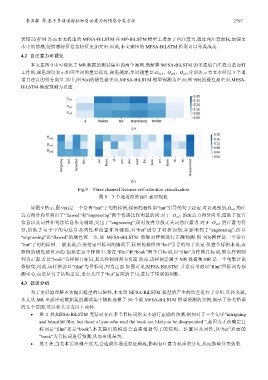
本文在图 9 中可视化了 MR 数据的测试集中的两个案例,来解释 MFSA-BiLSTM 的多通道自注意力是如何
工作的.颜色深度表示相应单词的重要程度.颜色越深,单词越重要.O ve1 、O ve2 、O ve3 分别表示为文本经过 3 个通
道自注意的得分向量.其中,图 9(a)的极性是正面,MFSA-BiLSTM 模型预测为正面;图 9(b)的极性是正面,MFSA-
BiLSTM 模型预测为负面.
(a)
(b)
Fig.9 Three channel features self-attention visualization
图 9 3 个通道特征自注意可视化
如图 9 所示,图 9(a)是一个带有“but”子句的样例,样例的极性由“but”引导的句子决定.可以观察到,O ve1 的注
意力得分向量突出了“flawed”和“engrossing”两个情感比较明显的词.对于 O ve2 的注意力得分向量,借助了位置
信息以及词性和句法信息作为辅助,突出了“engrossing”,同时没有分散无关词的注意力.对于 O ve3 的注意力得
分,借助了句子中的句法以及词性和位置作为辅助,对“but”进行了转折加强,并影响到了“engrossing”,所以
“engrossing”比“flawed”的颜色深一点.故 MFSA-BiLSTM 能够对样例进行正确预测.图 9(b)同样是一个带有
“but”子句的样例.一般来说,在没指定目标词的情况下,样例的极性由“but”引导的句子决定.从整个样例来说,该
样例的极性是负面的.但是在这个样例中,存在“film”和“book”两个目标词,以“film”为样例目标词,那么样例则
判为正面.若以“book”为样例目标词,那么样例则判为负面.然而,该样例是属于 MR 数据集,MR 是一个电影评论
数据集,因此,该样例要以“film”为目标词,判为正面.如图可见,MFSA-BiLSTM 并没有考虑以“film”目标词为预
测中心,而是从句子结构出发,重点关注了“but”后面的子句,进行了错误的判断.
4.3 错误分析
为了更好地理解本文提出模型的局限性,本文对 MFSA-BiLSTM 模型所产生的误差进行了分析.具体来说,
本文从 MR 电影评论数据集的测试集中随机选择了 50 个被 MFSA-BiLSTM 错误预测的实例,揭示了分类错误
的几个原因.可以将其分为以下两种.
• 第 1 种,MFSA-BiLSTM 无法对存在多个目标词的文本进行正确的预测.例如对于一个句子“intriguing
and beautiful film, but those of you who read the book are likely to be disappointed.”,会因为无法确定目
标词是“film”还是“book”,本文提出的模型会直接根据句子的结构、位置以及词性,以“but”后面的
“book”为目标词进行预测,从而出现误判;
• 第 2 种,当文本长短相差过大,会造成多通道特征稀疏,影响自注意力权重的分布,从而影响分类效果.