
Page 337 - 《软件学报》2020年第9期
P. 337
2958 Journal of Software 软件学报 Vol.31, No.9, September 2020
(a) 批大小为 64
(b) 批大小为 1
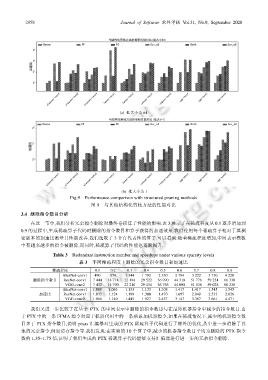
Fig.9 Performance comparison with structured pruning methods
图 9 与其他结构化剪枝方法的性能对比
3.4 删除指令数目分析
在这一节中,我们分析冗余指令删除对最终卷积算子性能的影响.表 3 展示了在稀疏程度从 0.1 逐步增加到
0.9 的过程中,生成稀疏算子代码时删除的指令数目和算子获得的加速效果.我们使用每个稀疏算子相对于其稠
密版本的加速比衡量其性能改善.我们选取了 3 个有代表性的算子.可以看到:随着稀疏程度增加,中间表示模板
中有越来越多的指令被删除,而同时,稀疏算子代码的性能也逐渐提升.
Table 3 Redundant instruction number and speedups under various sparsity levels
表 3 不同稀疏程度下删除的冗余指令数目和加速比
稀疏程度 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
AlexNet-conv1 490 974 1 344 1 792 2 330 2 784 3 222 3 730 4 220
删除指令数目 ResNet-conv1 7 444 14 718 22 194 29 522 36 990 44 318 51 776 59 254 66 330
VGG-conv2 7 432 14 790 22 210 29 434 36 766 44 098 51 536 59 028 66 238
AlexNet-conv1 1.000 1.063 1.133 1.133 1.308 1.417 1.417 1.545 1.545
加速比 ResNet-conv1 1.035 1.124 1.189 1.300 1.470 1.697 2.049 2.533 2.826
VGG-conv2 1.066 1.140 1.445 1.927 2.457 3.147 3.387 3.661 4.471
我们又进一步比较了在基于 PTX 的中间表示中删除的指令数目与在最终机器指令中减少的指令数目.由
于 PTX 中的一条 FFMA 指令对应于机器代码中的一条乘累加机器指令,如果在稀疏情况下,减少的机器指令数
目多于 PTX 指令数目,说明 ptxas 汇编器对生成的 PTX 稀疏算子代码进行了额外的优化,从中进一步消除了其
他的冗余指令,例如访存指令等.我们发现:在实验的 10 个算子中,减少的机器指令数目平均为删除的 PTX 指令
数的 1.35~1.75 倍,证明了我们生成的 PTX 稀疏算子代码能够支持汇编器进行进一步的冗余指令删除.