
Page 338 - 《软件学报》2020年第9期
P. 338
董晓 等:面向稀疏卷积神经网络的 GPU 性能优化方法 2959
3.5 访存优化分析
在这一节中,我们对稀疏卷积代码生成方法中的访存优化技术的直接效果进行评估.由于英伟达 GPU 上的
性能剖析工具 nvprof 不支持直接测量常量内存和常量缓存的访问情况,我们使用两个其他指标间接说明优化
的效果.首先,我们测试全局内存的平均访问吞吐量.由于对稀疏参数的访问不再经过全局内存,与位于全局内
存中的输入数据使用了不同的访问路径,避免了相互之间的干扰,因此全局内存的访问吞吐量可以获得提升.另
外,我们也测量了 DRAM 的平均访问吞吐量,观察同时使用全局内存和常量内存对 DRAM 吞吐量的改进.
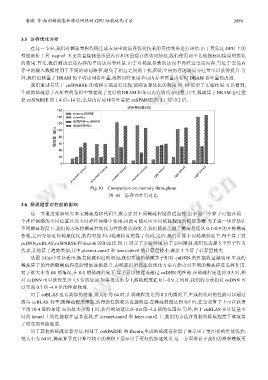
我们通过与基于 cuSPARSE 的卷积实现进行比较,说明访存优化的效果.图 10 展示了实验结果.可以看到,
生成的稀疏算子在所有的卷积中都实现了更好的 DRAM 和全局内存访问吞吐量.其中,稀疏算子 DRAM 吞吐量
是 cuSPARSE 的 1.4 倍~14 倍,全局内存访问吞吐量是 cuSPARSE 的 1.1 倍~3.2 倍.
Fig.10 Comparison on memory throughput
图 10 访存吞吐量对比
3.6 稀疏程度对性能的影响
这一节通过实验研究本文稀疏卷积代码生成方法对不同稀疏程度的适应性.由于同一个算子可能在同一
个神经网络的不同位置以及不同神经网络中使用,因此可能对应不同稀疏程度的模型参数.为了进一步评估在
不同稀疏程度下,我们的方法将稀疏性转化为性能收益的能力,我们随机生成了稀疏程度从 0.1~0.9 的 9 种稀疏
参数,之后分别进行稀疏优化,获得对应不同稀疏程度的算子代码.之后,我们计算不同稀疏程度下,每个算子对
cuDNN,cuBLAS,cuSPARSE 和 Escoin 的加速比.图 11 展示了实验结果.由于空间限制,我们仅选择 5 个算子作为
代表,其他算子趋势类似,其中,alexnet-conv2 和 lenet-conv2 的计算量较小,剩余 3 个算子计算量较大.
从图 11(a)中可以看出:随着稀疏程度的增加,我们生成的稀疏算子相对 cuDNN 的性能收益越明显.生成的
稀疏算子的性能随稀疏程度的增加逐渐提升,表明我们所提出的优化方法有能力对不同的稀疏程度发挥作用.
对于批大小为 64 的情况,在 0.1 的稀疏程度下,算子可以接近或超过 cuDNN 的性能.在稀疏程度达到 0.5 时,相
对 cuDNN 可以获得至少 1.5 倍的加速.如果批大小为 1,稀疏程度在 0.1~0.9 之间时,我们的方法相对 cuDNN 可
以实现 0.7 倍~4.9 倍的性能收益.
对于 cuBLAS 也有类似的结果,批大小为 64 时,在稀疏程度达到 0.2 的情况下,生成的代码的性能可以超过
或与 cuBLAS 持平;随稀疏程度增加,获得的性能收益也越明显.在稀疏程度达到 0.5 时,在全部算子上可以获得
平均 10.4 倍的加速.而当批大小为 1 时,获得的加速比在 0.6 倍~3.2 倍的范围内.另外,由于 cuBLAS 在计算量不
同的 kernel 上的性能存在显著差异,在 alexnet-conv2 和 lenet-conv2 上,我们的方法在很低的稀疏程度下就取得
了明显的性能收益.
对于其他的稀疏计算方法,相对于 cuSPARSE 和 Escoin,生成的稀疏卷积算子展示出了更明显的性能优势.
批大小为 64 时,稀疏算子在计算量较小的卷积上展示出了更好的加速效果.这一方面得益于我们的卷积模板更