
Page 283 - 《软件学报》2026年第1期
P. 283
280 软件学报 2026 年第 37 卷第 1 期
1 引 言
数据库系统是现代信息技术的重要组成部分, 广泛应用于各类数据密集型场景中. 数据库系统已从早期简单
的存储系统发展为支持数据共享、决策与隐私保护的复杂系统. 数据库系统的核心任务是高效、可靠地存储、管
理和检索数据, 而在数据库系统中促进高效完成这一系列任务的核心组件就是查询优化器. 查询优化器作为数据
库系统中的重要组件, 它的主要功能是找出一条查询语句所对应的最优查询计划, 从而最小化查询执行的代价.
传统查询优化器会采用相对静态的优化策略以保证在尽可能多的应用场景下发挥作用, 其优化方式的缺陷主
要体现在以下 3 点.
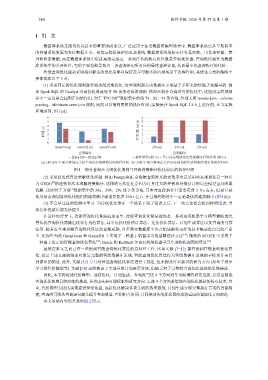
(1) 采用固定的优化规则进行流水线式地优化. 这些规则都是由数据库专家基于多年来的经验手动编写的. 例
如 Spark SQL 的 Catalyst 查询优化器就包含 50 余条这样的规则. 然而在部分查询语句的优化中, 这些固定的规则
[1]
并不一定总是会起到正面的作用, 对于 TPC-DS 数据集中的第 74、82、93 条查询, 分别关闭 reorder join、column
pruning、eliminate outer join 规则, 反而可以得到更短的执行时间 (实验是在 Spark SQL 3.4.0 上进行的, 本节实验
环境后同, 图 1(a)).
6 6
5 5
4 4
时间 (s) 3 2 时间 (取 ln) (s) 3 2
1 1
0 0
query74.sql query82.sql query93.sql 29a.sql 29b.sql 29c.sql
查询编号 查询编号
基准时间 优化时间 基准时间 (取 ln) 开启动态规划优化连接顺序后的时间 (取 ln)
(a) TPC-DS 中部分查询在关闭个别优化规则前后的执行时间 (b) JOB 中部分查询在开启动态规划优化连接顺序前后的执行时间
图 1 部分查询在关闭优化规则与开启连接顺序优化前后的执行时间
(2) 采用启发式算法求解优化问题. 例如 PostgreSQL 会根据查询涉及的表数来决定采用动态规划还是一种名
为 GEQO 的遗传算法来求解连接顺序. 这样的方法往往会因为自身过大的开销和基数估计的误差错过全局的最
[2]
[3]
优解. 比如对于 JOB 数据集中的 29a、29b、29c 这 3 条查询, 其本身直接执行只需要花费 3–8 s 左右, 但是只是
使用动态规划算法优化他们的连接顺序就需要花费 210 s 左右, 并且得到的还不一定是最优的连接顺序 (图 1(b)).
(3) 不会从过往的经验中学习. 当传统优化器在一个场景下犯了错误之后, 下一次它依然会犯同样的错误, 导
致总体性能长期无法提升.
在这样的背景下, 智能查询优化算法应运而生. 智能查询优化算法指的是一系列运用机器学习模型辅助或代
替传统查询优化器做出优化行为的算法, 其中包括代价估计算法、连接优化算法、计划生成算法以及查询改写算
法等. 随着近年来智能查询优化算法的逐渐成熟, 许多商业数据库中也开始逐渐将这样的技术集成进自己的产品
中, 比如华为的 OpenGauss 和 GaussDB 上实现了一种基于机器学习的基数估计方法 [4] ; 微软的 SCOPE 中采用了
一种基于提示的智能查询优化算法 [5] ; Oracle 和 RedShift 中也有利用机器学习生成物化视图的算法 [6] .
虽然在本文之前已有一些提到智能查询优化算法的总结性工作, 比如文献 [7−12] 都有提到智能查询优化算
法, 但是上述文献的综述对象是完整的智能数据库系统, 智能查询优化算法作为智能数据库系统的子模块并未得
到详尽的阐述. 此外, 文献 [13] 专门对智能查询优化算法进行了综述, 但未提及许多新兴的研究方向 (如基于排序
学习的代价模型等). 文献 [14] 虽然覆盖了大部分的计划表示方法, 但缺乏对于完整的查询优化算法的系统描述.
因此, 本文将综述代价模型、连接优化、计划生成、查询改写这 4 个方面近年来取得的研究进展, 总结出智能
查询优化领域目前面临的挑战, 并指出未来可能探索的研究方向. 上述 4 个方面是智能查询优化算法的核心技术, 其
中, 代价模型为优化决策提供量化依据, 连接优化解决多表关联的效率瓶颈, 计划生成实现完整执行方案的智能构
建, 查询改写则从查询语句源头提升查询质量. 它们相互协同, 共同推动传统优化器向动态适应的智能化方向演进.
本文后续内容的关系如图 2 所示.