
Page 288 - 《软件学报》2026年第1期
P. 288
何家豪 等: 智能查询优化算法研究综述 285
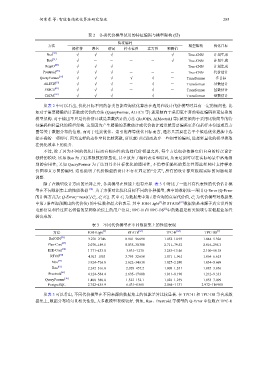
表 2 各类代价模型使用的特征编码与模型架构 (续)
特征编码
方法 模型架构 优化目标
操作符 表名 谓词 样本位图 直方图 预测值
[39]
Neo √ √ √ - - √ Tree-CNN 计划生成
[61]
Bao √ - - - - √ Tree-CNN 计划生成
[40]
DeepO √ √ √ - - - Tree-CNN 计划生成
[41]
Prestroid √ √ √ - - - Tree-CNN 代价估计
[36]
QueryFormer √ √ √ √ √ - Transformer 多目标
[37]
ALECE √ √ √ - √ - Transformer 基数估计
[62]
PRICE √ √ √ - √ - Transformer 基数估计
[43]
CEDA √ √ √ - √ - Transformer 基数估计
从表 2 中可以看出, 优化目标不同的各类智能查询优化算法在选用和设计代价模型时具有一定的倾向性. 比
如对于需要精确估计基数或代价的方法 (QueryFormer, ALECE 等) 就更倾向于采用更丰富的特征编码和更复杂的
模型架构. 对于输出不只是代价估计或是基数估计的方法 (ReJOIN, AIMeetsAI 等) 就更倾向于采用比较简单的特
征编码和轻量化的模型架构. 这是因为产生精确的基数估计或代价估计通常就需要编码更多包括样本位图或直方
图等关于数据分布的信息. 而对于连接优化、索引推荐等优化目标而言, 通常只需要在若干个候选优化措施中选
择正确的一项即可. 因为这样的动作空间比较离散, 所以就可以进而放弃一些细节的编码, 选择轻量化的模型换取
在优化效率上的提升.
不过, 除了因为不同的优化目标而有倾向性的选择代价模型之外, 每个方法也会依据它们自身的特点设计
独特的模块. 比如 Bao 为了追求极致的轻量化, 甚至放弃了编码表名和谓词, 从而达到可以在实际场景中落地级
别的实用性; 又如 QueryFormer 为了达到其多目标优化的通用性, 不惜特征编码的复杂性而选择同时支持样本
位图和直方图的编码. 这也说明了代价模型的设计不存在固定的“公式”, 所有的设计都应根据实际的问题场景
调整.
除了在模型设计方面的差异之外, 各类模型在性能上也有差异. 表 3 中对比了一些具有代表性的代价估计模
型在不同数据集上的性能数据 [14] . 为了方便对比优化目标不同的各种模型, 表中的数据统一采用 Q-Error (Q-Error
C C /C i ). 其中 C i 为数据集中第 i 条查询的真实代价值, C 为代价模型对数据集
,
′
′
′
的计算方式为: Q-Error i =max(C i / i i i
[3]
中第 i 条查询预测出的代价值) 的中位数和最大值表示. 其中 JOB-Light 和 STATS [63] 数据集是来源于真实世界的
[1]
电影信息和经过匿名转储的某网络论坛上的用户信息; TPC-H 和 TPC-DS 中的数据是相关领域专家根据业务经
验合成的.
表 3 不同代价模型在不同数据集上的性能表现
方法 JOB-Light [3] STATS [63] TPC-H [64] TPC-DS [1]
ReJOIN [59] 3.276–2 746 8.941–96 690 1.052–14.93 1.044–5.326
Plan-Cost [47] 2.070–189.5 8.035–30 380 2.711–79.52 2.016–295.3
E2E-Cost [38] 1.771–433.0 3.831–1 270 3.253–13.46 2.100–50.18
RTOS [60] 4.013–1853 3.793–32 650 1.071–1.961 1.064–6.615
Neo [39] 3.924–716.0 2.622–34 630 1.027–2.240 1.034–5.669
Bao [61] 2.242–316.0 2.028–457.2 1.008–1.331 1.085–3.956
Prestroid [41] 4.324–584.4 2.695–17 600 1.011–8.196 1.212–9.333
QueryFormer [36] 1.408–380.0 1.322–132.1 1.028–1.259 1.053–7.499
PostgreSQL 2.742–455.9 6.431–8 565 2.064–1 131 2.972–116 900
从表 3 可以看出, 不同代价模型在不同来源的数据集上的性能差异比较显著. 在 TPC-H 和 TPC-DS 等合成数
据集上, 数据分布均匀且相关性低, 大多数模型表现较好. 例如, Bao、Prestroid 等模型的 Q-Error 中位数在 TPC-H