
Page 291 - 《软件学报》2026年第1期
P. 291
288 软件学报 2026 年第 37 卷第 1 期
3.3 使用强化学习对连接进行优化
为了解决这些挑战, 近年来出现了基于强化学习的连接优化算法. 这些方法利用强化学习模型从过去的实例
中获取经验, 从而减少了因为代价估计错误而造成的连接顺序和方式错误. 同时它们的开销也比传统优化器的动
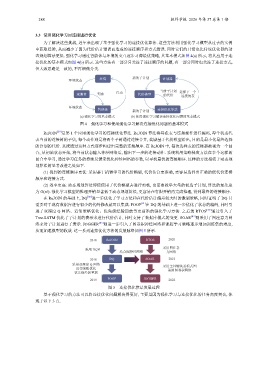
态规划算法更低. 强化学习通过智能体与环境的交互逐步习得最优策略, 其基本模式如图 4(a) 所示, 将其应用于连
接优化的基本模式如图 4(b) 所示. 这些方法有一部分只关注了连接顺序的问题, 有一部分同时也关注了连接方式,
但大致思路是一致的, 不再细做分类.
环境状态 环境 新的子计划 计划器
观测者 奖励 行动 代价模型 当前子计划 选择下一个
的代价
连接的表
环境状态
智能体 新的子计划 连接优化算法
(a) 强化学习的基本模式 (b) 使用强化学习解决连接优化问题的基本模式
图 4 强化学习和使用强化学习解决连接优化问题的基本模式
ReJOIN [59] 是第 1 个应用强化学习的连接优化算法. ReJOIN 算法将每张表与连接操作进行编码, 每个状态代
表当前的连接树的子集, 每个动作则是将两个子树通过连接合并, 奖励基于代价模型给出, 目的是最小化最终选择
的计划的代价. 系统通过这种方式逐步构建出完整的连接顺序. 在 ReJOIN 中, 每次选择表的连接都被视为一个回
合, 从初始状态开始, 将当前状态输入神经网络后, 输出下一步的连接动作. 系统利用策略梯度方法在多个这样的
回合中学习, 通过学习任务的持续反馈来优化神经网络的参数, 以寻找最优的连接顺序. 这样的方法相较于动态规
划算法的显著改进之处如下.
(1) 找到的连接顺序更优: 采用基于机器学习的代价模型, 代价估计更准确, 更容易选择出正确的低代价连接
顺序和连接方式.
(2) 效率更高: 动态规划算法即使使用了代价模型去进行剪枝, 也需要枚举大量的候选子计划, 算法的复杂度
为 O(n!). 强化学习模型的推理开销显著低于动态规划算法, 更容易在有限开销内完成推理, 得到最终的连接顺序.
在 ReJOIN 的基础上, DQ [80] 进一步优化了学习方法和在代价估计偏差较大时的微调策略, 同时证明了 DQ 只
需要对于现有数据库进行很少的代码修改就可以集成. FOOP [81] 在 DQ 的基础上进一步优化了状态的编码, 同时引
进了双深度 Q 网络、近邻策略优化、优先级经验回放等更前沿的强化学习方法. 之后的 RTOS [60] 通过引入了
Tree-LSTM 优化了子计划的表示来进行代价估计, 同时支持了数据库模式的变更. SOAR [82] 则采用了图注意力网
络来对子计划进行了表示. JOGGER [83] 则进一步引入了图卷积神经网络和课程学习策略逐步增加训练集的难度,
从而加速模型的收敛. 这一系列连接优化方法的发展脉络如图 5 所示.
2018 ReJOIN RTOS 2020
采用图注意
采用 DQN
结合图神经网络 力网络
2018 DQ SOAR 2022
采用双深度 Q 网络 采用主外键关系模式图
近邻策略优化 采用图卷积网络
优先级经验重放
2019 FOOP JOGGER 2022
图 5 连接优化算法发展过程
基于强化学习的方法可以将连接优化问题解决得更好, 主要是因为强化学习与连接优化的任务高度契合, 体
现于以下 3 点.