
Page 462 - 《软件学报》2025年第12期
P. 462
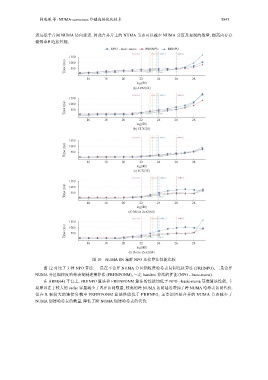
韩瑞琛 等: NUMA-conscious 外键连接优化技术 5843
迟远低于片间 NUMA 访问延迟, 因此合并片上的 NUMA 节点可以减少 NUMA 分区及复制的数量, 提高内存存
储效率和连接性能.
NPO --basic-numa PSNNPO RRNPO
1 500
Time (ms) 1 000
500
16 18 20 22 24 26 28
log(|R|)
(a) ARM(64)
1 500
Time (ms) 1 000
500
16 18 20 22 24 26 28
log(|R|)
(b) CLX(28)
1 500
Time (ms) 1 000
500
16 18 20 22 24 26 28
log(|R|)
(c) ICX(38)
1 500
Time (ms) 1 000
500
16 18 20 22 24 26 28
log(|R|)
(d) Milan Zen3(64)
1 500
Time (ms) 1 000
500
16 18 20 22 24 26 28
log(|R|)
(e) Rome Zen2(64)
图 10 NUMA SN 集群 NPO 连接算法性能比较
图 12 对比了 3 种 NPO 算法: 一是在不合并 NUMA 分区细粒度哈希表复制连接算法 (FRHNPO), 二是合并
NUMA 分区细粒度哈希表复制连接算法 (FRHNPONM), 三是 baseline 算法的性能 (NPO --basic-numa).
在 ARM(64) 平台上, FRHNPO 算法和 FRHNPONM 算法的性能均低于 NPO --basic-numa 基准算法性能, 主
要原因在于较大的 cache 容量减少了内存访问数量, 较高的跨 NUMA 访问延迟增加了跨 NUMA 哈希表访问代价.
但在 R 表较大的连接负载中 FRHNPONM 算法性能优于 FRHNPO, 主要原因是合并的 NUMA 节点减少了
NUMA 创建哈希表的数量, 降低了跨 NUMA 创建哈希表的代价.