
Page 457 - 《软件学报》2025年第12期
P. 457
5838 软件学报 2025 年第 36 卷第 12 期
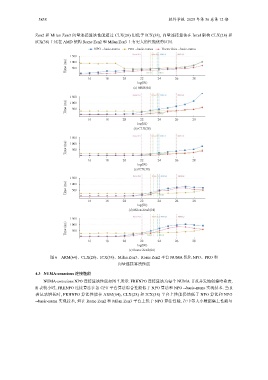
Zen2 和 Milan Zen3 向量连接算法性能超过 CLX(28) 但低于 ICX(38), 向量连接算法在 Intel 架构 CLX(28) 和
ICX(38) 上比在 AMD 架构 Rome Zen2 和 Milan Zen3 上有更大的性能优势区间.
NPO --basic-numa PRO --basic-numa Vector Join --basic-numa
1 500
Time (ms) 1 000
500
16 18 20 22 24 26 28
log(|R|)
(a) ARM(64)
1 500
Time (ms) 1 000
500
16 18 20 22 24 26 28
log(|R|)
(b) CLX(28)
1 500
Time (ms) 1 000
500
16 18 20 22 24 26 28
log(|R|)
(c) ICX(38)
1 500
Time (ms) 1 000
500
16 18 20 22 24 26 28
log(|R|)
(d) Milan Zen3(64)
1 500
Time (ms) 1 000
500
16 18 20 22 24 26 28
log(|R|)
(e) Rome Zen2(64)
图 6 ARM(64)、CLX(28)、ICX(38)、Milan Zen3、Rome Zen2 平台 NUMA 优化 NPO、PRO 和
向量连接算法性能
4.3 NUMA-conscious 连接性能
NUMA-conscious NPO 连接算法性能如图 7 所示. FRHNPO 连接算法为每个 NUMA 节点并发地创建哈希表,
R 表较小时, FRHNPO 连接算法在各 CPU 平台算法综合性能低于 NPO 算法和 NPO --basic-numa 实现技术. 当 R
表记录增长时, FRHNPO 算法性能在 ARM(64), CLX(28) 和 ICX(38) 平台上性能仍然低于 NPO 算法和 NPO
--basic-numa 实现技术, 但在 Rome Zen2 和 Milan Zen3 平台上优于 NPO 算法性能. 在中等大小数据集上性能与