
Page 458 - 《软件学报》2025年第12期
P. 458
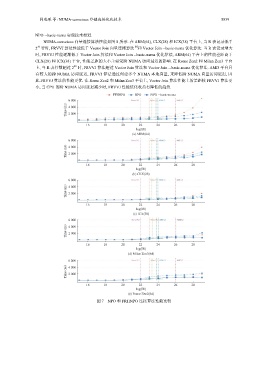
韩瑞琛 等: NUMA-conscious 外键连接优化技术 5839
NPO --basic-numa 实现技术相近.
NUMA-conscious 向量连接算法性能如图 8 所示. 在 ARM(64), CLX(28) 和 ICX(38) 平台上, 当 R 表记录低于
26
2 行时, FRVVJ 算法性能优于 Vector Join 向量连接算法 [9] 和 Vector Join --basic-numa 优化算法. 当 R 表记录增大
时, FRVVJ 性能逐渐低于 Vector Join 算法和 Vector Join --basic-numa 优化算法, ARM(64) 平台上的性能差距高于
CLX(28) 和 ICX(38) 平台, 性能差距的大小主要受跨 NUMA 访问延迟的影响. 在 Rome Zen2 和 Milan Zen3 平台
上, 当 R 表行数超过 2 时, FRVVJ 算法超过 Vector Join 算法和 Vector Join --basic-numa 优化算法. AMD 平台具
28
有较大的跨 NUMA 访问延迟, FRVVJ 算法通过创建多个 NUMA 本地向量, 来降低跨 NUMA 向量访问延迟, 因
此 FRVVJ 算法的性能更优. 在 Rome Zen2 和 Milan Zen3 平台上, Vector Join 算法性能上的差距较 FRVVJ 算法更
小, 当 CPU 的跨 NUMA 访问延迟减少时, FRVVJ 性能优化收益有降低的趋势.
FPHNPO NPO NPO --basic-numa
6 000
Time (ns) 4 000
2 000
16 18 20 22 24 26 28
log(|R|)
(a) ARM(64)
6 000
Time (ns) 4 000
2 000
16 18 20 22 24 26 28
log(|R|)
(b) CLX(28)
6 000
Time (ns) 4 000
2 000
16 18 20 22 24 26 28
log(|R|)
(c) ICX(38)
6 000
Time (ns) 4 000
2 000
16 18 20 22 24 26 28
log(|R|)
(d) Milan Zen3(64)
6 000
Time (ns) 4 000
2 000
16 18 20 22 24 26 28
log(|R|)
(e) Rome Zen2(64)
图 7 NPO 和 FRHNPO 连接算法性能比较