
Page 463 - 《软件学报》2025年第12期
P. 463
5844 软件学报 2025 年第 36 卷第 12 期
PSNVJ Vector Join --basic-numa
800
600
Time (ms) 400
200
16 18 20 22 24 26 28
log(|R|)
(a) ARM(64)
800
Time (ms) 400
600
200
16 18 20 22 24 26 28
log(|R|)
(b) CLX(28)
800
600
Time (ms) 400
200
16 18 20 22 24 26 28
log(|R|)
(c) ICX(38)
800
600
Time (ms) 400
200
16 18 20 22 24 26 28
log(|R|)
(d) Milan Zen3(64)
800
600
Time (ms) 400
200
16 18 20 22 24 26 28
log(|R|)
(e) Rome Zen2(64)
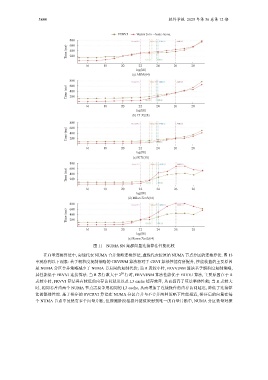
图 11 NUMA SN 集群向量连接算法性能比较
在向量连接算法中, 实线代表 NUMA 合并策略连接算法, 虚线代表按原始 NUMA 节点分区的连接算法. 图 13
中观察到以下现象: 基于粗粒度复制策略的 CRVJNM 算法相对于 CRVJ 算法性能有所提升, 性能收益的主要原因
是 NUMA 分区合并策略减少了 NUMA 节点间的复制代价; 当 R 表较小时, FRVVJNM 算法基于细粒度复制策略,
28
其性能低于 FRVVJ 连接算法. 当 R 表行数大于 2 行时, FRVVJNM 算法性能优于 FRVVJ 算法, 主要原因在于 R
表较小时, FRVVJ 算法具有较低的内存访问延迟以及 L3 cache 缓存效率, 从而提高了算法整体性能; 当 R 表较大
时, 相同芯片内两个 NUMA 节点需要争用相同的 L3 cache, 从而增加了连接操作的内存访问延迟, 降低了连接算
法的整体性能. 基于排序的 SVCRVJ 算法在 NUMA 分区合并与不合并两种策略下性能相近, 排序后的向量在每
个 NUMA 节点中虽然有多个向量片断, 但探测阶段根据外键值映射到唯一的向量片断中, NUMA 分区数量对探