
Page 464 - 《软件学报》2025年第12期
P. 464
韩瑞琛 等: NUMA-conscious 外键连接优化技术 5845
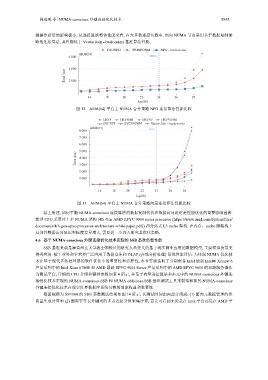
测操作延迟的影响极小; 从连接算法整体性能来看, 在大多数连接负载中, 面向 NUMA 节点采用基于数据复制策
略的连接算法, 其性能低于 Vector Join --basic-numa 基准算法性能,
FRHNPO FPHNPONM NPO --basic-numa
ARM(64)
6 000
Time (ms) 4 000
2 000
16 18 20 22 24 26 28
log(|R|)
图 12 ARM(64) 平台上 NUMA 合并策略 NPO 连接算法性能比较
CRVJ CRVJNM FRVVJ FRVVJNM
SVCRVJ SVCRVJNM Vector Join --basic-numa
ARM(64)
8 000
7 000
6 000
5 000
Time (ms) 4 000
3 000
2 000
1 000
16 18 20 22 24 26 28
log(|R|)
图 13 ARM(64) 平台上 NUMA 合并策略向量连接算法性能比较
综上所述, 如何平衡 NUMA-conscious 连接算法的数据复制代价和数据访问延迟是性能优化的重要影响因素.
新型 CPU 采用片上多 NUMA 架构 (4th Gen AMD EPYC 9004 series processor (https://www.amd.com/system/files/
documents/4th-gen-epyc-processor-architecture-white-paper.pdf)) 和分离式 L3 cache 架构, 在内存、cache 微架构上
局部性数据访问延迟和粒度差异增大, 需要进一步深入研究其优化策略.
4.6 基于 NUMA-conscious 外键连接优化技术实现的 SSB 基准负载性能
SSB 基准负载是麻省州立大学波士顿校区的研究人员定义的基于现实商业应用的数据模型, 主要模拟决策支
持类应用, 被工业界和学术界广泛应用于数据仓库和 OLAP (在线分析处理) 系统性能评估. 为体现 NUMA 优化技
术在基于现代多核处理器的软件优化中的重要性和必要性, 本节实验选取了分别配备 Intel 最新 Intel® Xeon® 6
产品系列中的 Intel Xeon 6780E 和 AMD 最新 EPYC 9004 Series 产品系列中的 AMD EPYC 9654 的双路服务器作
为测试平台, 详细的 CPU 介绍和硬件参数如表 4 所示, 并基于向量连接算法和本文中的 NUMA-conscious 外键连
接优化技术实现的 NUMA-conscious-SSB 和 NUMA-oblivious-SSB 基准测试工具来模拟和探究 NUMA-conscious
外键连接优化技术在现实世界数据库系统负载的性能收益和重要性.
数据规模为 SF=100 的 SSB 基准测试结果如图 14 所示, 其测试时间由两部分组成: (1) 面向元数据管理的维
向量生成计算和 (2) 面向事实表外键列的多表连接分组聚集计算, 首先可看到无论是在 Intel 平台还是在 AMD 平