
Page 456 - 《软件学报》2025年第12期
P. 456
韩瑞琛 等: NUMA-conscious 外键连接优化技术 5837
法则是 NUMA 性能低敏感型连接算法. 向量连接算法较高的 cache 效率和较低的 NUMA 敏感性可以降低 NUMA
优化需求, 通过较低的算法复杂度达到较高的性能.
Improvement (%)-NRO --basic-numa Improvement (%)-PRO --basic-numa Improvement (%)-Vector Join --basic-numa
Improvement (%)-NRO Improvement (%)-PRO Improvement (%)-Vector Join
Time (ms)-NRO Time (ms)-PRO Time (ms)-Vector Join
Time (ms)-NRO --basic-numa Time (ms)-PRO --basic-numa Time (ms)-Vector Join --basic-numa
3 000 160 1 600 60 1 200 120
2 500 140 1 400 40 1 000 100
120 1 200 20 800 80
2 000
ARM(64) Time (ms) 1 500 80 Improvement (%) Time (ms) 1 000 0 −20 Improvement (%) Time (ms) 600 60 Improvement (%)
60
40
800
600
40
20
1 000
400
500 20 400 −40 200 0 −20
0 200
0 −20 0 −60 0 −40
5 7 9 11 13 15 17 19 21 23 25 27 29 5 7 9 11 13 15 17 19 21 23 25 27 29 5 7 9 11 13 15 17 19 21 23 25 27 29
log(|R|) log(|R|) log(|R|)
3 000 80 1 200 70 1 000 35
900 30
2 500 60 1 000 60 800 25
700
50
20
Time (ms) 2 000 40 Time (ms) 800 40 Improvement (%) Time (ms) 600 15
0
500
10
1 500
600
CLX(28) 1 000 Improvement (%) 30 400 5 Improvement (%)
200
−20
500 20 400 20 300 0 −5
200
10
−10
100
0 −40 0 0 0 −15
5 7 9 11 13 15 17 19 21 23 25 27 29 5 7 9 11 13 15 17 19 21 23 25 27 29 5 7 9 11 13 15 17 19 21 23 25 27 29
log(|R|) log(|R|) log(|R|)
1 400 100 800 80 600 25
1 200 80 700 70 500 20
15
1 000 60 600 60 400 10
500
50
ICX(38) Time (ms) 800 40 Improvement (%) Time (ms) 400 40 Improvement (%) Time (ms) 300 5 0 −5 Improvement (%)
600
400 0 300 30 200 −10
20
−15
200
200 20 100 10 100 −20
0 −20 0 0 0 −25
5 7 9 11 13 15 17 19 21 23 25 27 29 5 7 9 11 13 15 17 19 21 23 25 27 29 5 7 9 11 13 15 17 19 21 23 25 27 29
log(|R|) log(|R|) log(|R|)
2 500 160 1 000 50 900 30
140 900 45 800
2 000 120 800 40 700 20
10
700
35
100
600
60
25
500
Rome Zen2 Time (ms) 1 500 80 Improvement (%) Time (ms) 600 30 Improvement (%) Time (ms) 500 0 −10 Improvement (%)
400
400
40
20
1 000
200
200
500 20 300 15 300 −20
0
10
−30
−20 100 5 100
0 −40 0 0 0 −40
5 7 9 11 13 15 17 19 21 23 25 27 29 5 7 9 11 13 15 17 19 21 23 25 27 29 5 7 9 11 13 15 17 19 21 23 25 27 29
log(|R|) log(|R|) log(|R|)
2 500 250 700 60 800 20
600 50 700 10
2 000 200 500 40 600 0
Time (ms) 1 500 150 400 30 500 −10
400
Milan Zen3 1 000 100 Improvement (%) Time (ms) 300 Improvement (%) Time (ms) 300 −20 Improvement (%)
500 50 200 20 200 −30
10
100
100
0 0 0 0 0 −40
5 7 9 11 13 15 17 19 21 23 25 27 29 5 7 9 11 13 15 17 19 21 23 25 27 29 5 7 9 11 13 15 17 19 21 23 25 27 29
log(|R|) log(|R|) log(|R|)
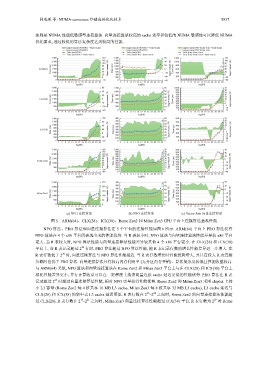
(a) NPO 连接算法 (b) PRO 连接算法 (c) Vector Join 向量连接算法
图 5 ARM(64)、CLX(28)、ICX(38)、Rome Zen2 和 Milan Zen3 CPU 平台上连接算法基准性能
NPO 算法、PRO 算法和向量连接算法在 5 个平台的连接性能如图 6 所示. ARM(64) 平台上 PRO 算法没有
NPO 算法在 4 个 x86 平台所表现出来的性能优势. 当 R 表较小时, NPO 算法与向量连接算法性能差异较 x86 平台
更大. 当 R 表较大时, NPO 算法性能与向量连接算法性能差异较其他 4 个 x86 平台更小. 在 CLX(28) 和 ICX(38)
23
平台上, 当 R 表记录超过 2 行时, PRO 算法超过 NPO 算法性能, 随 R 表记录行数的增长性能差异进一步增大. 在
20
R 表行数低于 2 时, 向量连接算法与 NPO 算法性能相近. 当 R 表行数增长时性能优势增大, 并且在较大 R 表连接
负载时也优于 PRO 算法. 向量连接算法具有较高内存利用率 (无分区内存开销)、算法复杂度较低且性能收益较高.
与 ARM(64) 类似, NPO 算法和向量连接算法在 Rome Zen2 和 Milan Zen3 平台上与在 CLX(28) 和 ICX(38) 平台上
相比性能差异更小, 并行计算收益可以在一定程度上抵消向量连接 cache 延迟更低的性能优势. PRO 算法在 R 表
23
记录超过 2 时超过向量连接算法性能, 相对 NPO 更早获得性能优势. Rome Zen2 和 Milan Zen3 采用 chiplet 上较
小 L3 容量 (Rome Zen2 每 4 核共享 16 MB L3 cache, Milan Zen3 每 8 核共享 32 MB L3 cache), L3 cache 延迟与
20
16
CLX(28) 和 ICX(38) 的集中式 L3 cache 延迟更低. R 表行数在 2 –2 之间时, Rome Zen2 的向量连接算法性能超
18
21
29
过 CLX(28), R 表行数在 2 –2 之间时, Milan Zen3 向量连接算法性能超过 ICX(38) 平台, R 表行数为 2 时 Rome