
Page 351 - 《软件学报》2025年第12期
P. 351
5732 软件学报 2025 年第 36 卷第 12 期
问是否有助于发现题文不符. 我们计算了评级的平均累积分数作为各评测方法的性能得分. 这些分数范围为 1–10,
其中 1 表示最差, 10 表示最好. 评级者的一致性通过 Randolph 的自由边际 Kappa 指标来衡量 [85] .
7.0 8.2 7.9
6.77 CLDInst Clickbait17 7.62 FakeNewsNet
7.55 7.59
6.59
6.5 6.49 6.48 6.41 7.5 7.54 7.42 7.4 7.35 7.41
6.27 6.33 7.30 7.25 7.22
6.13 6.31 6.21 6.26 7.22 7.23 7.14 7.15
6.21 7.07 7.15 7.03 7.11
6.18 6.20 6.18 6.14 6.94 7.07 7.05 7.08 7.07
6.04 6.95 7.01
6.04 6.83 6.90 6.87 6.88 6.81 6.78 6.98 6.88 6.86
6.0 5.93 6.8 6.71 6.74 6.9 6.83
5.85 6.57 6.76
6.64
6.29 6.22 6.25
5.54 5.50 5.52
5.5 5.43 6.1 6.04 6.4 6.28 6.35 6.30 6.32
5.0 5.4 5.9
w/o MulR w/o RaG w/o PCO w/o CQG w/o VVM w/o CVM w/o MulR w/o RaG w/o PCO w/o CQG w/o VVM w/o CVM w/o MulR w/o RaG w/o PCO w/o CQG w/o VVM w/o CVM
ACC PRE REC F1
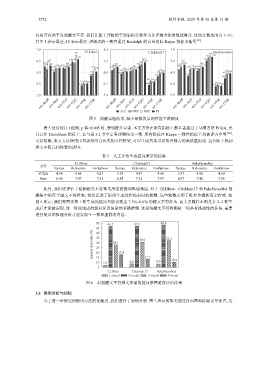
图 5 消融实验结果, 减少某模块后的性能下降幅度
表 5 使用统计 t 检验, p 值<0.005 时, 表明提升显著. 本文方法在所有指标上都显著超过了基准方法 FCQA, 尤
其是在 Usefulness 指标上. 这与第 3.2 节中定量评测结果一致. 所有指标在 Kappa 一致性指标上均被评为中等 [86] .
可以推断, 本文方法使用由易到难组合范式的可控框架, 可以生成具备常识推理能力的高质量提问. 这有助于找到
推文中隐式和伪装的诱饵.
表 5 人工评估生成提问质量的结果
CLDInst Clickbait17 FakeNewsNet
方法
Syntax Relevance Usefulness Syntax Relevance Usefulness Syntax Relevance Usefulness
FCQA 4.96 4.64 4.27 5.33 4.87 4.46 5.37 4.91 4.60
Ours 6.49 7.07 7.21 6.85 7.21 7.47 6.97 7.40 7.58
此外, 我们还评估了检测题文不符推文所需的提问推理难度. 对于 CLDInst、Clickbait17 和 FakeNewsNet 数
据集中的每个题文不符样本, 我们记录了提问生成过程结束时的轮数. 这些轮数表明了推理步骤和复杂程度. 如
图 6 所示, 我们观察到第 1 轮生成的提问只能识别出 7.3%–8.8% 的题文不符样本. 而大多数样本则是在 2–3 轮生
成后才能被识别, 这一阶段生成的提问涉及复杂的多跳推理. 这说明题文不符检测是一项具有挑战性的任务, 需要
进行复杂的推理分析才能发现不一致和虚假的内容.
50 46.7 47.2 48.4
45
Sample size ratio (%) 35 28.1 17.9 30.9 32.3
40
30
25
20
15
10 7.3 8.6 13.3 8.9 10.4
5
CLDInst Clickbait17 FakeNewsNet
1-round 2-round 3-round 4-round
图 6 识别题文不符推文所需的提问推理难度评估结果
3.5 案例分析与讨论
为了进一步探究所提出方法的优缺点, 我们进行了案例分析. 图 7 所示的推文通过封面图和标题误导读者, 造