
Page 173 - 《软件学报》2025年第9期
P. 173
4084 软件学报 2025 年第 36 卷第 9 期
算例 2: 非线性系统辨识. 系统如公式 (29) 所示 [38,39] .
2
y(t + 1) = 0.72y(t)+0.025y(t −1)x(t −1)+0.01x(t −2) +0.2x(t −3) (29)
,
其中, x(t) y(t) 分别表示系统在 t (t ⩾ 0) 时刻的输入与输出. 算例 2 的训练数据、测试数据、各网络模型参数设定
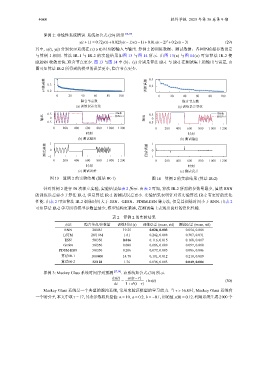
与算例 1 相同. 算法 IR-1 与 IR-2 的实验结果如图 13 与图 14 所示. 由图 13(a) 与图 14(a) 可知算法 IR-2 使
IRRNN 收敛更快, 隐含节点更少. 图 13 与图 14 中 (b)、(c) 分别是算法 IR-1 与 IR-2 在测试集上的输出与误差, 由
图可知算法 IR-2 所得到的模型的误差更小, 隐含节点更少.
训练误差 0.3 训练误差 0.2
0.4
0.2
0 20 40 60 80 100 0 20 40 60 80 100
隐含节点数 隐含节点数
(a) 训练误差变化 (a) 训练误差变化
0.5 实际值 0.5 实际值
输出 0 算法IR-1 输出 0 算法IR-2
−0.5 −0.5
0 200 400 600 800 1 000 1 200 0 200 400 600 800 1 000 1 200
时刻 时刻
(b) 测试输出 1 (b) 测试输出
1
测试误差 0 测试误差 0
−1
0 200 400 600 800 1 000 1 200 −1 0 200 400 600 800 1 000 1 200
时刻 时刻
(c) 测试误差 (c) 测试误差
图 13 算例 2 的实验结果 (算法 IR-1) 图 14 算例 2 的实验结果 (算法 IR-2)
针对算例 2 进行 50 次独立实验, 实验结果如表 2 所示. 由表 2 可知, 算法 IR-2 所需的参数量最少, 虽然 RNN
的训练误差要小于算法 IR-2, 但是算法 IR-2 的测试误差更小. 实验结果表明针对该实验算法 IR-2 有更好的泛化
性能. 由表 2 可知算法 IR-2 训练时间大于 ESN、GESN、PDSM-ESN 等方法, 但是其训练时间小于 RNN. 由表 2
可知算法 IR-2 学习所得模型参数量最少, 模型结构更紧凑, 在测试集上表现出良好的泛化性能.
表 2 算例 2 的实验结果
方法 隐含节点/参数量 训练时间 (s) 训练误差 (mean, std) 测试误差 (mean, std)
RNN 20/481 19.25 0.028, 0.003 0.054, 0.006
LSTM 20/1 861 1.81 0.242, 0.008 0.307, 0.031
ESN 50/350 0.016 0.116, 0.015 0.168, 0.017
GESN 50/350 0.088 0.086, 0.009 0.097, 0.010
PDSM-ESN 50/350 0.206 0.077, 0.005 0.086, 0.006
算法IR-1 100/400 14.78 0.181, 0.012 0.210, 0.019
算法IR-2 32/128 1.76 0.038, 0.003 0.049, 0.004
算例 3: Mackey Glass 系统时间序列预测 [27,34] . 该系统如公式 (30) 所示.
dx(t) ax(t −τ)
= +bx(t) (30)
n
dt 1+ x (t −τ)
τ > 16.8 时, Mackey Glass 系统有
Mackey Glass 系统是一个典型的混沌系统, 常用来验证模型的学习能力. 当
一个吸引子, 本文中取 τ = 17, 其余参数取典型值: n = 10, a = 0.2, b = −0.1, 初始值 x(0) = 0.12. 利用系统生成 2 000 个