
Page 184 - 《软件学报》2025年第7期
P. 184
赵冬冬 等: 结合特征生成与重放的可扩展安全虹膜识别 3105
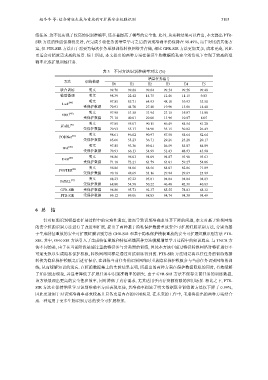
练任务. 这不仅实现了较高的识别准确率, 还显著提高了模型的安全性. 此外, 从实验结果可以看出, 本文提出 PTR-
SIR 方法的性能保持得更好, 在完成 5 轮任务的增量学习之后的识别准确率仍保持在 98.49%, 高于对比的其他方
案, 但 PTR-SIR 方法由于需要为每次任务单独训练转换网络并存储, 相比 GFR-SIR 方法更加复杂, 成本更高, 因此
更适合对精度需求高的场景. 综上所述, 本文提出的两种方案在保证生物数据隐私安全的情况下实现了较高的准
确率完成扩展训练任务.
表 3 不同方法识别准确率对比 (%)
增量任务编号
方法 训练数据
T0 T1 T2 T3 T4 T5
联合训练 明文 99.70 99.68 99.64 99.54 99.56 99.48
模型微调 明文 98.39 22.42 14.75 12.46 11.15 9.83
明文 97.85 85.71 64.93 48.10 39.93 33.58
LwF [40]
受保护数据 70.93 44.70 27.40 19.96 15.86 14.48
明文 97.98 51.58 31.94 21.15 16.87 15.08
[42]
EWC
受保护数据 71.18 40.01 20.00 13.96 10.07 8.05
明文 97.85 95.07 90.15 86.49 84.54 81.20
iCaRL [41]
受保护数据 70.93 55.17 38.90 35.15 30.82 26.43
明文 98.61 96.02 90.97 87.58 84.64 82.64
[43]
PODNet
受保护数据 65.66 53.23 36.71 29.26 25.28 20.17
明文 97.85 93.36 89.01 86.59 85.07 84.09
WA [44]
受保护数据 70.93 66.13 54.99 51.43 48.93 45.90
明文 98.86 96.03 94.09 94.87 93.90 93.63
[45]
DER
受保护数据 71.18 73.21 63.79 61.01 59.27 54.86
明文 98.86 94.06 88.56 84.07 82.86 71.89
FOSTER [46]
受保护数据 70.18 48.69 33.16 29.94 29.67 25.99
明文 98.23 97.22 95.81 94.84 94.84 94.83
[47]
FeTrIL
受保护数据 68.80 54.58 50.22 46.48 42.31 40.83
GFR-SIR 受保护数据 98.80 95.73 92.37 85.55 78.03 68.32
PTR-SIR 受保护数据 99.12 99.06 98.83 98.74 98.39 98.49
6 总 结
针对虹膜识别模型在扩展过程中的灾难性遗忘, 进而导致识别准确率显著下降的问题, 本文对基于转换网络
的安全虹膜识别方法进行了改进和扩展, 提出了两种基于隐私保护数据重放安全可扩展虹膜识别方法, 分别为基
于生成特征重放的安全可扩展虹膜识别方法 GFR-SIR 和基于隐私保护模板重放的安全可扩展虹膜识别方法 PTR-
SIR. 其中, GFR-SIR 方法引入了生成特征重放和特征蒸馏两种方法缓解增量学习过程中的知识遗忘. 与 TNCB 方
法不同的是, 由于在当前阶段是通过重放特征参与分类器的训练, 因此本方法中通过特征转换网络对特征进行不
可逆变换以生成隐私保护模板, 转换网络同样是通过对抗训练得到的. PTR-SIR 方法则是将以往任务的训练数据
转换为隐私保护模板之后进行保存, 在训练当前任务的识别网络时重放隐私保护模板参与当前任务识别网络的训
练, 从而缓解知识的遗忘. 在虹膜数据集上的实验结果表明, 所提出的两种方案在保护数据隐私的同时, 有效缓解
了知识遗忘现象, 并显著降低了扩展任务中识别准确率的损失. 由于 GFR-SIR 方法不保存先前任务的训练数据,
该方法展现出更高的安全性和效率, 同时降低了内存需求, 尤其适用于内存资源有限的应用场景. 相比之下, PTR-
SIR 方法在保持增量学习识别准确率方面表现更佳, 其准确率相较于明文数据联合训练的方法仅下降了 0.99%,
因此更适用于对识别准确率要求较高且具备充足内存的应用场景. 在未来的工作中, 考虑将提出的两种方案结合
成一种适用于更多生物识别方法的安全可扩展框架.