
Page 179 - 《软件学报》2025年第7期
P. 179
3100 软件学报 2025 年第 36 卷第 7 期
k
f = max acc l,j −acc k,j (17)
j
l∈{ j,...,k−l}
f 之后, 本文中同样通过加权平均的方式计算得到任务 的平均
k
k
在计算得到任务 k 之前每个任务的遗忘指标 j
遗忘 F k , 计算方法如下:
k−l
∑
k
(w j × f )
j
j=0
F k = (18)
k ∑
w j
j=0
5.2 性能和遗忘评估
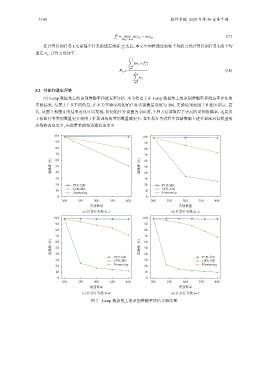
(1) Lamp 数据集上的识别准确率和遗忘率评估. 本节给出了在 Lamp 数据集上的识别准确率和遗忘率评估的
实验结果, 与第 5.1 节不同的是, 在本节实验中将初始任务类别数量设置为 200, 实验结果如图 7 和图 8 所示. 首
先, 从图 7 和图 8 的结果对比可以发现, 将初始任务设置为 200 时, 3 种方法都取得了更高的识别准确率. 这是由
于初始任务类别数量更多则用于扩展训练的类别数量就更少, 在扩展任务过程中在新数据上进行训练对旧模型的
参数修改也更少, 由此带来的知识遗忘也更少.
100
100
90 90
80 80
70 70
准确率 (%) 50 准确率 (%) 60
60
50
40
30 40
30
20 PTR-SIR 20 PTR-SIR
GFR-SIR GFR-SIR
10 10
Finetuning Finetuning
0 0
200 250 300 350 400 200 250 300 350 400
类别数量 类别数量
(a) 扩展任务数 K=1 (b) 扩展任务数 K=2
100 100
90 90
80 80
70 70
准确率 (%) 60 准确率 (%) 60
50
50
40
PTR-SIR 40 PTR-SIR
30 GFR-SIR 30 GFR-SIR
Finetuning Finetuning
20 20
10 10
0 0
200 250 300 350 400 200 250 300 350 400
类别数量 类别数量
(c) 扩展任务数 K=4 (d) 扩展任务数 K=5
图 7 Lamp 数据集上的识别准确率评估实验结果