
Page 85 - 《软件学报》2024年第4期
P. 85
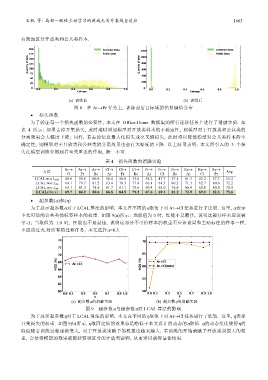
王帆 等: 局部一致性主动学习的源域无关开集域自适应 1663
有效地区分开放类和公共类样本.
(a) 训练前 (b) 训练后
图 8 在 Ar→Pr 任务上, 训练前后目标域的信息熵值分布
• 损失函数
为了验证每一个损失函数的必要性, 本文在 Office-Home 数据集的所有迁移任务上进行了消融实验. 如
表 4 所示: 如果去掉开集损失, 此时难以增加模型对开放类样本的不确定性, 则模型对于开放类和公共类的
分离效果会大幅度下降; 同样, 若去掉信息最大化损失或交叉熵损失, 此时难以降低模型对公共类样本的不
确定性, 则模型对于开放类和公共类的分离效果也会有大幅度的下降. 以上结果表明: 本文所引入的 3 个损
失在模型训练中都起着至关重要的作用, 缺一不可.
表 4 损失函数的消融实验
Ar→ Ar→ Ar→ Cl→ Cl→ Cl→ Pr→ Pr→ Pr→ Re→ Re→ Re→
方法 Avg
Cl Pr Re Ar Pr Re Ar Cl Re Ar Cl Pr
LCAL w.o L unk 49.6 58.6 60.9 56.4 56.0 53.6 58.2 47.7 57.1 61.3 45.2 57.3 55.2
LCAL w.o L kn 64.1 79.7 81.2 63.4 78.3 77.8 66.1 61.3 80.2 71.3 62.7 80.6 72.2
LCAL w.o L im 63.1 81.3 78.6 61.7 81.1 73.6 60.4 65.0 76.8 66.4 62.8 80.0 70.9
LCAL(Ours) 69.7 84.2 80.6 66.8 84.5 79.3 67.6 69.1 81.2 72.9 69.1 82.3 75.6
• 超参数(α)和(η)
为了展示超参数α对于 LCAL 算法的影响, 本文在不同的α取值下对 Ar→Cl 任务进行了比较. 这里, α表示
不太可信的公共类伪标签样本的权重. 如图 9(a)所示: 当取值为 0 时, 性能不是最佳, 说明这部分样本应该被
学习; 当取值为 1.0 时, 性能也不是最佳, 说明这部分不可信样本的权重不应该设置和主动标注的样本一样,
不应该过大.对所有的迁移任务, 本文选择α=0.3.
(a) 超参数α的消融实验 (b) 超参数η的消融实验
图 9 超参数α与超参数η对 LCAL 算法的影响
为了展示超参数η对于 LCAL 算法的影响, 本文在不同的η取值下对 Ar→Cl 任务进行了比较. 这里, η表示
开集损失的权重. 如图 9(b)所示, η取固定值的效果总是略低于本文设计的动态的η取值. η的动态变化使得η的
取值随着训练过程逐渐变大, 对于开放类别赋予的权重也越来越大. 若训练的开始就赋予开放类别很大的权
重, 会使得模型的效果被那些错误区分的开放类影响, 从而难以获得最佳结果.