
Page 161 - 《软件学报》2024年第4期
P. 161
钱鸿 等: 基于动态批量评估的绿色无梯度优化方法 1739
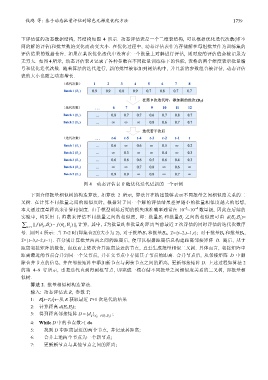
下评估值的动态数据结构, 其结构如图 4 所示. 动态评估表是一个二维表结构, 可以根据优化迭代次数(即不
同的解的评估)和批量数的变化而改变大小. 在优化过程中, 动态评估表作为存储解在每组批量作为训练集的
评估结果的数据仓库. 如果在某次优化迭代中没有在一个批量上对解进行评估, 则对应的评估值会被记录为
无穷大. 如图 4 所示, 动态评估表 R 记录了各种参数在不同批量训练集下的性能, 表格的两个维度表示批量编
号和优化迭代次数. 随着算法的迭代进行, 新的批量被添加到树结构中, 并且新的参数组合被评估, 动态评估
表的大小也随之动态增长.
图 4 动态评估表 R 随优化迭代更新的一个示例
下面介绍批量相似树的构造算法, 如算法 2 所示, 算法旨在构建能够表示不同批量之间相似度关系的二
叉树. 在计算不同批量之间的相似度时, 根据对于同一个解的评估结果差异越小的批量相似度越大的思想,
−2
−4
本文通过度量距离来计算相似度. 由于模型训练后期的损失或准确率通常在 10 ~10 数量级, 因此在后续的
实验中, 均采用 l 1 范数来评估不同批量之间的相似度, 即: 批量 i 和批量 j 之间的相似度可由 d( i , j )=
|| ( , ) − f θ∑ f θ ( , ) || 计算, 其中, 为批量 i 和批量 j 距离当前最近 T 次评估的同时评估的迭代次数序
k∈ k i k j 1
号. 如图 4 所示: 当 T=2 时(即集合的大小为 2), 对于批量 1 和批量 2 , ={t−2,t−1,t}; 对于批量 4 和批量 5 ,
={t−3,t−2,t−1}. 在分别计算批量两两之间的距离后, 便可以根据距离信息构建距离邻接矩阵 D. 随后, 基于
距离邻接矩阵的数值, 自底而上依次合并距离最近的节点, 直至生成批量相似二叉树. 具体而言, 邻接矩阵中
距离最近的节点合并到同一个父节点, 并在父节点中存储其子节点的距离. 合并节点后, 从邻接矩阵 D 中删
除合并节点的信息, 并在邻接矩阵中添加新节点与剩余节点之间的距离, 更新邻接矩阵 D. 上述过程如算法 2
的第 4−9 行所示, 重复迭代直到得到根节点, 即完成一棵存储不同批量之间相似度关系的二叉树, 即批量相
似树.
算法 2. 批量相似树构造算法.
输入: 动态评估表 R, 参数 T;
1: R[t−T,t]←从 R 获取最近 T+1 次迭代的结果
2: 计算距离 d( i , j );
3: 得到距离邻接矩阵 D = {}d ij d ij d= ( i , j ) ;
4: While D 中的节点数>1 do
5: 找到 D 中距离最近的两个节点, 并记录其距离;
6: 合并上述两个节点为一个新节点;
7: 更新新节点与其他节点之间的距离;