
Page 166 - 《软件学报》2021年第9期
P. 166
2790 Journal of Software 软件学报 Vol.32, No.9, September 2021
加权后的注意力特征向量 O sve :
O sve =w satt ⊗V SLN (20)
最后,使用 softmax 函数对其进行分类.
softmax
O sve
w satt
so
ft
Doc. Self-
m
w
Attention
S
t ax
V
S 1 S 2 ... S m
... ... ... LSTM LSTM LSTM
x 11 x 12 x 1n x 21 x 22 x 2n x m1 x m2 x mn LSTM LSTM ... LSTM
SAMF- SAMF- SAMF-
BiLSTM 1 BiLSTM 2 ... BiLSTM m
S att1 S att2 ... S attm
S att1 S att2 S attm
Word representation Sentence representation
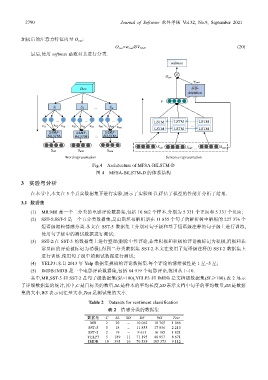
Fig.4 Architecture of MFSA-BILSTM-D
图 4 MFSA-BiLSTM-D 的体系结构
3 实验与分析
在本节中,本文在 5 个真实数据集下进行实验,展示了实验细节,评估了模型的性能并分析了结果.
3.1 数据集
(1) MR:MR 是一个二分类的电影评论数据集,包括 10 662 个样本,分别为 5 331 个正面和 5 331 个负面;
(2) SST-5:SST-5 是一个五分类数据集,是由斯坦福解析器在 11 855 个句子的解析树中解析的 227 376 个
短语级细粒情感分类.本文在 SST-5 数据集上分别对句子级和基于短语级注释的句子级上进行训练,
使用句子级中的测试数据进行测试;
(3) SST-2:在 SST-5 的数据集上进行整理(删除中性评论,非常积极和积极的评论被标记为积极,消极和非
常负面的评论被标记为消极),得到二分类数据集 SST-2.本文在使用了短语级注释的 SST-2 数据集上
进行训练,使用句子级中的测试数据进行测试;
(4) YELP3:来自 2013 年 Yelp 数据集挑战的评论数据集.每个评论的情绪极性是 1 星~5 星;
(5) IMDB:IMDB 是一个电影评论数据集,包括 84 919 个电影评论,范围从 1~10.
其中,MR,SST-5 和 SST-2 是句子级数据集(SL<100),YELP3 和 IMDB 是文档级数据集(SL≥100).表 2 显示
了详细数据集的统计,其中,C 是目标类的数量,SL 是样本的平均长度,SD 表示文档中句子的平均数量,DS 是数据
集的大小,WS 表示词汇量大小,Test 是测试集的大小.
Table 2 Datasets for sentiment classification
表 2 情感分类的数据集
数据集 C SL SD DS WS Test
MR 2 20 − 10 062 18 765 1 066
SST-5 5 18 − 11 855 17 836 2 210
SST-2 2 19 − 9 613 16 185 1 821
YELP3 5 189 11 71 193 48 957 8 671
IMDB 10 395 16 76 538 105 373 9 112