
Page 162 - 《软件学报》2021年第9期
P. 162
2786 Journal of Software 软件学报 Vol.32, No.9, September 2021
节),目的是为了让模型从不同角度去学习情感特征信息,充分地挖掘句子中的隐藏信息.
softmax
Output Merge S att
O ve2 O ve3
O ve1
w att1 w att2 w att3
sof sof sof
Self-
Self-
Self-
tm tm tm
Attention_1
Attention_3
w
Self-Attention a 1 ax Attention_2 a 3
w ax
w ax
a 2
t t t
Layer
Normalization V LN1 V LN2 V LN3
LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM
... ... ... LSTM
Bidirectional LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM
LSTMs
W d
... ... ...
Word Tag Pos Par
Representation
w 1 w 2 w n w 1 w 2 w n w 1 w 2 w n
R wt R wp R wpa
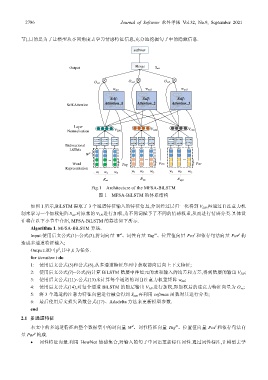
Fig.1 Architecture of the MFSA-BiLSTM
图 1 MFSA-BiLSTM 的体系结构
如图 1 所示,BiLSTM 提取了 3 个通道特征输入的特征信息,分别经过层归一化得到 V LN ,再通过自注意力机
制来学习一个加权矩阵 S att 对原来的 V LN 进行加权,为不同词赋予了不同的情感权重,从而进行情感分类.具体设
计将在以下小节中介绍, MFSA-BiLSTM 的算法如下所示.
Algorithm 1. MFSA-BiLSTM 算法.
m
p
d
l
Input:使用后文公式(1)~公式(3),将词向量 W 、词性向量 Tag 、位置值向量 Pos 和依存句法向量 Par 构
造成多通道特征输入;
k
Output:返回 p ,其中,k 为任务.
for iteration t do
1: 使用后文公式(5)和公式(6),从多通道特征序列中获取前向后向上下文特征;
2: 使用后文公式(7)~公式(9)计算 BiLSTM 隐层中神经元的求和输入的均差和方差,得到隐层的输出 V LN ;
3: 使用后文公式(11)~公式(13)来计算每个通道的词自注意力权重矩阵 w att ;
4: 使用后文公式(14),对每个通道 BiLSTM 的隐层输出 V LN 进行加权,即加权后的注意力特征向量为 O ve ;
5: 将 3 个通道的注意力特征向量进行融合得到 S att ,再利用 softmax 函数对其进行分类;
6: 最后使用后文损失函数公式(17)、Adadelta 方法来更新模型参数.
end
2.1 多通道特征
m
l
d
本文中的多通道特征由整个数据集中的词向量 W 、词性特征向量 Tag 、位置值向量 Pos 和依存句法向
p
量 Par 构成.
• 词性特征向量.利用 HowNet 情感集合,对输入的句子中词语重新标注词性.通过词性标注,让模型去学