
Page 95 - 《爆炸与冲击》2026年第5期
P. 95
第 46 卷 冯 彬,等: 基于图神经网络的可燃气体泄漏扩散预测方法 第 5 期
3.2 时空预测精度
为确保对 MSDGNN 与 MGN 模型进行公平的比较,训练时采用的超参数均保持一致,如消息传递
层数(L)、隐藏层大小(N)、邻居节点数(k)和学习率(l )等。通过调整式 (3) 中 A 和 B 的取值,实现了不
r
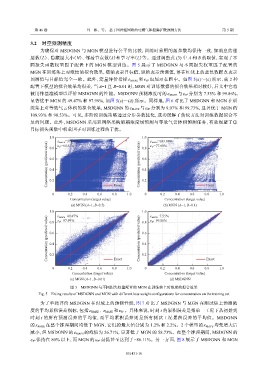
同损失函数权重因子配置下的 MGN 模型训练。图 5 展示了 MSDGNN 与不同损失权重因子配置的
MGN 在训练集上对浓度的拟合效果,横轴表示目标值,纵轴表示预测值,落在红线上的蓝色数据点表示
ε R 2 也展示在图中。如图 5(a)~(c) 所示,前 种
预测值与目标值完全一致。此外,定量评价指标 ε MAPE 和 2
配置下模型的拟合效果均很差,当 A=1 且 B=0.01 时,MGN 对训练数据的拟合效果相对较好,后文中它将
被用作基准模型以评价 MSDGNN 的性能。MSDGNN 预测浓度时的 ε MAPE 与 ε R 2 分别为 7.55% 和 99.86%,
显著优于 MGN 的 49.47% 和 97.99%,如图 5(c)~(d) 所示。同样地,图 6 对比了 MSDGNN 和 MGN 在训
练集上对等效气云体积的拟合效果,MSDGNN 的 ε MAPE 与 ε R 2 分别为 9.07% 和 99.73%,显著优于 MGN 的
108.93% 和 90.53%。可见,多阶段训练策略通过分步参数优化,成功缓解了传统方法对训练数据拟合不
足的问题。此外,MSDGNN 采用双网络架构解耦浓度场预测与等效气云体积预测任务,有效规避了单
目标损失函数中权重因子对训练过程的干扰。
1.0 1.0
ε MAPE =371.07% 0.8 ε MAPE =693.06%
Concentration (predicted value) 0.6 Concentration (predicted value) 0.6
ε R 2=77.68%
ε R 2=64.61%
0.8
0.4
0.4
0.2
Exact
Exact
0 0.2 0.4 0.6 0.8 1.0 0.2 0 0.2 0.4 0.6 0.8 1.0
Concentration (target value) Concentration (target value)
(a) MGN (A=1, B=0.5) (b) MGN (A=1, B=0.1)
1.0 ε MAPE =49.47% 1.0 ε MAPE =7.55%
Concentration (predicted value) 0.6 Concentration (predicted value) 0.6
ε R 2=99.86%
ε R 2=97.99%
0.8
0.8
0.4
0.4
0.2
Exact
Exact
0 0.2 0.4 0.6 0.8 1.0 0.2 0 0.2 0.4 0.6 0.8 1.0
Concentration (target value) Concentration (target value)
(c) MGN (A=1, B=0.01) (d) MSDGNN
图 5 MSDGNN 与不同损失权重配置的 MGN 在训练集上对浓度的拟合效果
Fig. 5 Fitting results of MSDGNN and MGN with different loss weight configurations for concentration on the training set
为了单独评价 MSDGNN 在时域上的预测性能,图 7 对比了 MSDGNN 与 MGN 在测试集上预测浓
ε R 2 。具体来说,时刻 t 的累积误差是指单一工况下从初始到
度的平均累积误差指标,包括 ε RMSE 、 ε MAPE 和
时刻 t 的所有预测误差的平均值,而平均累积误差则是所有测试工况累积误差的平均值。MSDGNN
ε RMSE 在整个推理期间均低于 MGN,它们的最大值分别为 1.2% 和 2.2%。2 ε MAPE 均先增大后
的 个模型的
减小,但 MSDGNN 的 ε MAPE 的峰值为 26.71%,显著低于 MGN 的 58.73%。在整个推理期间,MSDGNN 的
ε R 2 保持在 80% 以上,而 MGN 的 ε R 2 最低甚至达到了−86.11%。另一方面,图 8 展示了 MSDGNN 和 MGN
051431-10